
Figure 1: A record from the historical literature corpus showing the 'tagstract' used to illustrate the index metadata terms
Project Background | Summary of Archaeotools project objectives | The creation of frequency counts from the PSAS datasets | Conclusion
The Archaeotools project addressed practical issues in applying advanced computer science techniques to datasets generated in the Arts and Humanities and attempted to solve two key problems that have emerged in the field of archaeological informatics. The first concerns the creation of search mechanisms that go beyond the naïve and potentially unreliable text string approach of the classic search engine search box, as employed by Google for example. The second is how to generate the data that underpin such sophisticated searches automatically; that is, data such as 'what', 'where' and 'when' terms, that actually help the user to find a particular resource (i.e. resource discovery metadata).
An aspiration of the ADS was the development of a methodology that would allow automated metadata generation from digital versions of grey literature. While the need to do this for grey literature is pressing because of academic interest in the material (see Bradley 2006), the same methodology could be applied to digitised versions of other potential research resources such as early or very short-run published material. The ADS hold significant amounts of this type of 'legacy' material, for example the Proceedings of the Society of Antiquaries of Scotland (PSAS) from 1851 to 1999. Currently this material is only searchable by browsing through indexes of volumes by date and further browsing through article titles; the text itself is amenable to text string searches by external search engines but, as previously mentioned, this is an unreliable and naïve approach in terms of the relevance of results, especially for the purposes of focused research.
The main search interface into all the datasets made available and aggregated by the ADS is called ArchSearch III, which evolved from the ADS's original ArchSearch online catalogue developed in the late 1990s. The Archaeotools project was designed to develop this search mechanism further into a faceted classification browser with an associated interactive geospatial search. The facet classification approach to presenting structured datasets is now common on the web for commercial applications, but lends itself to the discovery of any structured dataset. For a description of its commercial use Denton (2003) gives a good introduction to the concepts behind faceted classification.
Previous work carried out on faceted classification by the ADS in a precursor project to Archaeotools called 'Archaeobrowser' and detailed in their report to the JISC's Common Information Environment Working Group (see Jeffrey et al. 2008), demonstrated that the most appropriate search facets for the archaeological datasets indicated above are:
What - what does the record refer to?
When - what is the archaeological date (range) of interest?
Where - what is the location or region of interest?
Media - what is the form of the record you are ultimately interested in?
These are obviously far from being the only possible facets and some others can be seen as highly desirable, such as 'Who' i.e. to whom does the record relate? Nonetheless, as a matter of practicality these four facets generally offer the greatest utility for the archaeological researcher.
In order to be capable of being browsed each facet needs to have an associated ontology, expressed as a hierarchy of terms, underpinning it. Fortunately, in the historic environment sector there are hierarchical thesauri already deployed or under development that make it possible to populate a browsing structure for each facet, apart from 'Media'. These thesauri, or controlled word lists, have been generated via a number of sources but it is key to their usefulness and sustainability that each has a controlling body, is recognised as a de jure or de facto standard and is either already being used or is in the process of being adopted. Each record in the target dataset is assigned a What, When and Where value from the selected thesauri. Just how powerful this approach is on a normalised dataset is demonstrated by a user's ability to drill down to a specific (and complete) set of records with the minimum of clicks. In tests on the Archaeobrowser system it was possible to go from the maximum number of 1,000,000 or so records to a selected set of 16 records representing Bronze Age funerary monuments within 5km of a specific location in North Yorkshire with just three or four clicks of the mouse (depending on the route taken). The mechanism adopted by the Archaeotools project was Solr an open source enterprise search server based on the Lucene Java search library.
Project Background | Summary of Archaeotools project objectives | The creation of frequency counts from the PSAS datasets | Conclusion
The primary objective of the Archaeotools project was the creation of an advanced faceted classification and geo-spatial browser. The underlying dataset comprised over 1,000,000 records (held in Oracle RDBMS) aggregated from the National Monuments Records of Scotland, Wales and England as well as Historic Environment Records from numerous local authorities and the ADS's own archive holdings. The facets selected were the standard hierarchical 'What', 'Where', and 'When' facets plus a 'Media' facet to allow the selection of particular subsets of resources. The facets were populated from existing thesauri (e.g. the Thesaurus of Monument Types) in XML format and extended/integrated to allow for geographical differences, such as terminological differences in monument and period types between Scotland and England. The Archaeotools project also used thesauri made available online in XML format by Simple Knowledge Organisation Systems (SKOS) based web services developed by the AHRC-funded Semantic Tools for Archaeology project (STAR), based at the University of Glamorgan. In order to populate the facetted search the project embarked on the creation of a reusable Natural Language Processing (NLP) system that automatically extracted resource discovery metadata (and other facet types) from unpublished archaeological reports. Of particular interest here is the extension of the NLP systems to capture metadata from legacy historical documents, using the PSAS as an exemplar corpus and utilising the University of Edinburgh's EDINA Unlock Places service to recast place names and locations extracted from text as national grid references (NGRs), allowing enhanced geospatial searching of the data.
Project Background | Summary of Archaeotools project objectives | The creation of frequency counts from the PSAS datasets | Conclusion
The Proceedings of the Society of Antiquaries of Scotland has been published by the Society in Edinburgh since 1851, appearing on a regular annual basis from the 1870s onwards. The journal generally consists of peer-reviewed articles, but also contains annual reports of society activities, lists of fellows and obituaries. The longevity and prestigious nature of the PSAS has ensured it remains an important channel for the publication of current archaeological results and thinking as well as representing an invaluable research resource for anyone interested in Scottish archaeology. For the reader, the nature of the language used in early volumes of PSAS is substantially different in tone and even syntactical construction from that used in modern-day grey literature; however, in the experience of the Archaeotools project, and from a NLP perspective, the text is still amenable to automated metadata extraction.
Here is an example section of text from an early PSAS paper:
'The bronze ring inscribed with runic characters, presented to the Society, was found in the year 1849, in the Abbey Park, in the immediate neighbourhood of St Andrews. It is a large bronze finger ring inscribed on the two faces in Anglo-Saxon runes, and is of peculiar interest, as being, it is believed, the only example of the Paleography of our Anglo-Saxon forefathers hitherto found in Scotland, with the single, but most important exception of the noble monument at Ruthwell, Dumfriesshire' (Wilson 1851)
Using NLP the following data (named entities) can potentially be extracted from it.
What - Bronze Ring, Runic Inscription (also 'the monument at Ruthwell')
Where - Abbey Park, St Andrews, (also Ruthwell, Dumfriesshire)
When - Anglo-Saxon (also 'found 1849')
Who - Wilson, D.
Media - PSAS (PDF)
Clearly this type of extracted data would mesh perfectly with the already implemented faceted browsing interface discussed in earlier sections. However, a significant problem was how to differentiate what the article is actually referring to (a bronze ring) from incidentally referenced items (the monument at Ruthwell, better known as the Ruthwell Cross). Similarly, how do we distinguish the find spot (Abbey Park) from all the other place names and the date of the object (Anglo-Saxon) from the date of the find (1849)? This proved to be a significant issue for the NLP approach as these distinctions cannot easily be resolved programmatically. Although a number of fairly sophisticated attempts were made to try and resolve this, the one that proved most successful was actually a simple frequency count of the named entities in the top 10% of the document. The actual utility of this approach in assigning named entities is discussed elsewhere (Jeffrey et al. 2009a; 2009b; Richards et al. 2010).
While this process created an extremely useful metadata set for the historical corpus, there remained a level of inconsistency within the data that could lead to a number of false positive results i.e. results that may contain a search term but are not actually a desired result. An example of this might be a search for 'Tower' returning multiple records from 'Tower Hamlets' because the entity 'Tower' in 'Tower Hamlets' is recognised as a monument rather than as part of a place name. So as to mitigate this, but not reduce the utility of the indexed metadata further, it was decided to maintain this level of data extraction, but provide alongside an illustration of the associated metadata terms and their frequencies. This was termed a 'tagstract' in reference to the concept of the tag cloud used to display user-generated tag terms on the web. It is hoped that this will offer an immediate indication to the user of what terms the record has been indexed against and therefore why it might have been returned via a seemingly unrelated search.
In this example (Figure 1) the record has clearly been indexed strongly against 'grange' as a term from the NMR Monument Type Thesaurus, but from the record it is clear that its use is related to a person's name or title. The 'tagstract' quickly indicates what terms the record has been indexed against, allowing the user to make an instant judgement of its relevance. This concept is further discussed in Jeffrey et al. in press.
Figure 1: A record from the historical literature corpus showing the 'tagstract' used to illustrate the index metadata terms
In the process of generating the frequency counts to make these distinctions, we actually produced frequency counts for each set of named entities for each article in the entire run of the PSAS available from the ADS. These represent the actual frequency of place names, period and monument types within these journals year on year, from 1851 to 1999. A superficial examination of these counts made it apparent that they detailed, metrically, what, when and where was being written about each year of the journal and therefore, via the editorial process, what was considered significant at that time. It was clear that this could offer significant potential in the longitudinal consideration of changes in archaeological practice previously mentioned. By looking at the changes in terms used and their relative frequencies we might well be able to give a more concrete basis to the presumed biases in subject and area believed to exist in the literature.
When considering the single corpus of a learned journal over more than a century one would expect there to be inherent biases in the archaeology recorded and discussed in the literature. One would expect these biases to shift and alter over that period. The question we wanted to address was not what these biases were or how they are reflected, but simply to assess whether this sort of data might allow us to begin to identify and quantify these biases. The analyses we undertook are superficial and limited in scope, and based on data which we are obliged to qualify and excuse, but are aimed at assessing the potential of this sort of metric data in investigating historical change in historical corpora such as this.
We performed some basic cross-referencing of place names and period terms used through time, firstly to check if we could see biases and changes that we expected to be present, and then to see if we could identify trends that weren't so obvious. Initial analysis was done without reference to the documents themselves, only the word count data. This was followed by some sampling of the literature to cast more light on the some of the speculative conclusions we had drawn.
Figure 2 shows the most frequently used period terms over a 120-year period from 1880 through to 1999. It illustrates both the total frequency for each term per decade, and also the relative frequency of the different terms within each decade. The most obvious characteristic is the lack of prehistoric period term use in the early part of the sequence.
Reference to the Roman period is proportionally very significant in the early decades of the study period, but also remains popular throughout. A distinct change, however, appears to occur in the 1920s, when references to the Roman period drop dramatically in proportion to the other period terms in use. What appears to replace these Roman references is a burgeoning use of prehistoric period terms. Until that point only 'Prehistoric' and 'Bronze Age' occurred in the most frequently used terms. From the 1920s onwards 'Neolithic' and 'Iron Age' appear, and the total proportion of prehistoric period terms rises from about a quarter to about half of these most frequently referenced descriptions. Interestingly, the term 'Mesolithic' does not appear in this list until the 1980s.
It would be easy to assume that these changes reflect the changing focus of attention of the learned society of the time; that the early domination of the list by 'Roman' references reflected a classicist agenda and the influence of classical scholars on the Edinburgh-centric antiquarian community. When we look into the literature itself, however, we can see that monuments and finds of prehistoric date are widely reported and discussed throughout the period.
What is striking is the consistently empirical style of the writing; objects and sites are accurately drawn and described and there is a noticeable absence of any speculation over the antiquity of many items. Where the age of a monument or object is not known, it is not recorded. It might be noted, however, that an object is, for example, 'clearly not of Roman origin' or 'probably older than a Roman date'. This begins to replicate a situation we have noticed when attempting natural language processing on modern archaeological literature, where many periods are listed in a report by the absence of evidence of activity e.g. 'there was no evidence of Bronze Age activity on the site'. The use of 'Roman' not to denote Roman period material but as a period reference point for earlier material may well have inflated its relative frequency in these decades.
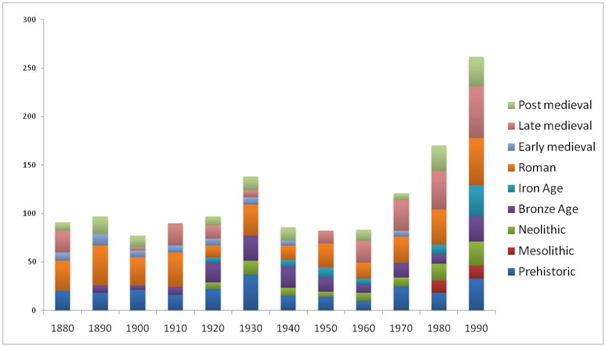
Figure 2: Counts for the most frequently used period terms by decade
Alongside this assessment of these most frequently used period terms, we considered the numbers of distinct period terms used over the study period (see Figure 3). This takes into account not only the most regularly used period terms, but all period terms recognised by the NLP extraction.
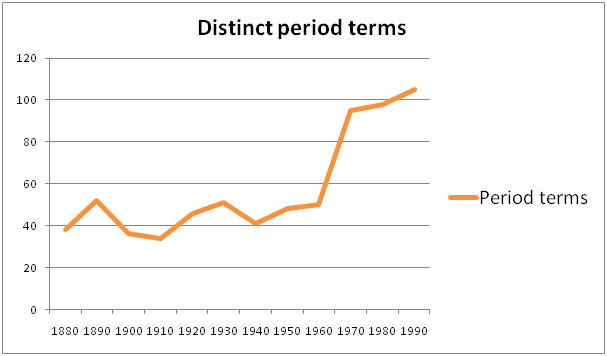
Figure 3: The number of distinct period terms recognised in the literature per decade.
These figures present us with a very clear event in the study period. In the 1970s the number of distinct period terms employed in the literature nearly doubles compared to the steady usage over the previous 90 years. There are a number of related factors that we could consider in explaining this mushrooming of period terms. We may be looking at the result of the increased availability of accurate dating technology. A more powerful influence could be the changing nature and scale of archaeological practice in Scotland at this time. With an increasing number of large-scale urban excavations being undertaken, this may be an artefact of the much finer-grained chronologies that such excavations produce. These factors in combination - improved dating and deeper, finer chronologies - could go some way to explaining these figures. A preliminary look at the literature itself suggests more references to radiocarbon dating in this period than previously. A further step would be to process the corpus against a thesaurus of techniques to see if we can quantify references to dating, excavation, and survey techniques more meaningfully.
The second set of metrics we considered related to the counts for indexed 'where' terms in the literature. This presented, at the first examination, a more complex and confused set of data, as illustrated in Figure 4. Without imposing some sort of order or structure against the place names identified in the text it is hard to extract any coherent picture from this. Returning to our original approach of testing against presumed or expected bias, we ordered some of the key terms to provide an approximate east to west transect across the country. One anecdotal bias in Scottish archaeological literature is that the more accessible eastern areas have been favoured by the Edinburgh-centric antiquarian community over the western side of the country. This presentation of the data can be seen in Figure 5.
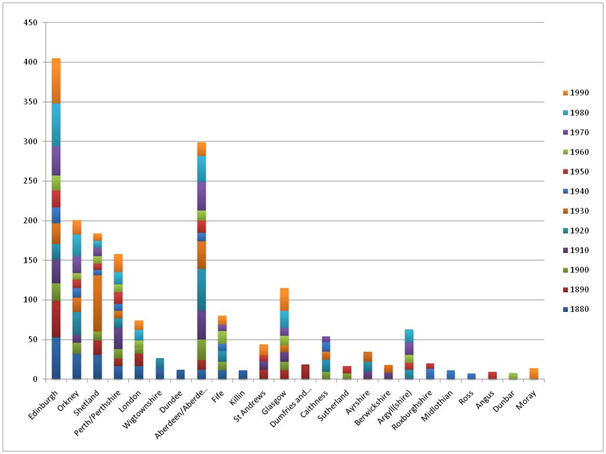
Figure 4: The breakdown and counts of the most used 'where' terms, by decade
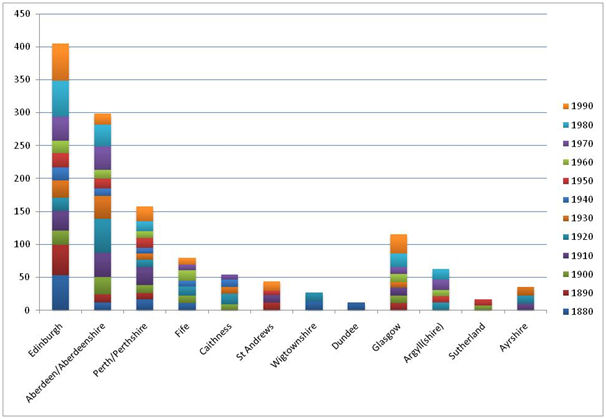
Figure 5: A selection of 'where' terms ordered into an approximate east-west transect
This presentation would seem to confirm the perceived bias noted earlier, with the most numerous eastern locations far outstripping their western counterparts. Glasgow, naturally, is mentioned a reasonable number of times, although it should be noted that nearly half of these citations occur within the last 30 years, coinciding with the late 20th-century boom in urban archaeology.
It must be understood that a minor, but significant, proportion of place names used in the earlier literature are references in personal and organisational addresses in the text. This would undoubtedly explain some of the dominance of Edinburgh in the figures, as both the centre of the antiquarian community and the home of many of the involved government agencies and learned societies. There may also be anomalies resulting from the repetition of the address details of particularly active researchers in other locations.
Differential preservation may be an archaeological factor of influence here. The western areas have been subject to heavier glacial stripping than the east, creating an environment less suited to either archaeological preservation or recovery than the more arable landscapes of the east. With this in mind, however, it is worth noting that Ayrshire in the west, but with an arable landscape, receives no mention in the literature until after 1970. So this preliminary review appears to do nothing to discredit the idea that there has been a historical eastern bias in the antiquarian literature in Scotland.
The final set of figures we considered in this superficial review was the variety of distinct place names used in the texts. Considered, again, by decade, the total number of places referred to produces an interesting profile (see Figure 6).
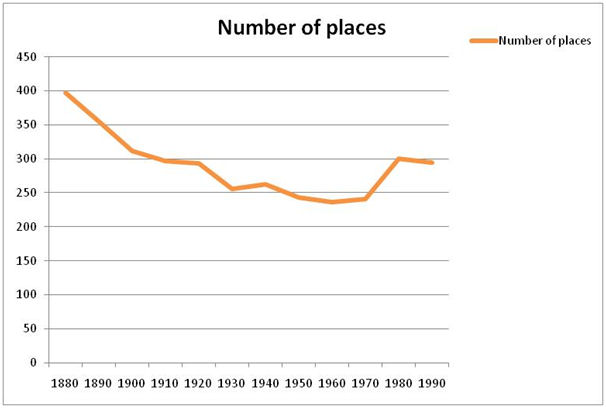
Figure 6: The number of distinct place names indexed per decade
There are three aspects to the profile presented in Figure 6 that provoke interest: firstly the steady decline in the number of places right though until the last few decades; secondly the notable drop in the number of distinct place terms between the 1920s and the 1930s; lastly, the increase in the number of 'where' terms from the 1970s onwards.
The gradual reduction in distinct place terms could have a number of underlying causes. The most prosaic might be that the trend for references to the personal addresses of Society members within the Proceedings reduces over this period. There may also be a gradual change in the style of place descriptions, perhaps containing less reference to proximal locations. A circumspect review of the table of contents pages of the Proceedings suggests a third, more interesting, factor that may be of relevance.
The early material of the corpus reflects the broad interests of the Society's membership in antiquarian matters throughout Europe, particularly from the Classical world, and perhaps reflecting the interest in antiquarian collecting. One might suppose that this interest was at the cost of a focus on Scottish archaeology, but a review of some of the articles seems to suggest otherwise. References to archaeological sites throughout Europe are very common in these early decades, but frequently these are given as parallels for recently discovered sites and finds in Scotland. The reduction in these 'foreign' place names appears to reflect a more self-confidently Scottish narrative in the descriptions. Comparisons cited in the later descriptions are more likely to be to Scottish sites, perhaps reflecting that a critical mass of commonly known and understood type-sites has been achieved, allowing sites to be described within an entirely Scottish context without need for speculative overseas parallels.
The two rather anomalous shifts in the figures, the sharp decrease in the 1920s and the subsequent increase 70 years later, may well be explained, at least in part, by the significant local government reorganisations that occur contemporaneously with them. The Local Government (Scotland) Act 1929 reduced the total number of local government bodies from over a thousand to 234. Although this is unlikely to have had an immediate effect upon how locations were referred to, within the decade-level granularity of our figures there is likely to have been an influence on how individual locations and areas were described.
Conversely the Local Government (Scotland) Act 1975 replaced some 33 counties created by the previous act with 12 regions containing 53 districts, adding considerably to the total number of area names that might be in use. Again, one would not expect this to change practice immediately but the changes seen in the coarse granularity of this review may well reflect changes caused by this legislation. This latter increase may have been magnified by the NLP as the modern place name lists employed may generate higher hit rates against this late sequence of the corpus.
Project Background | Summary of Archaeotools project objectives | The creation of frequency counts from the PSAS datasets | Conclusion
Although the analysis presented here is necessarily superficial, and many of the proposed influencing factors are speculative, the exercise has illustrated the rich level of useful historical data that can potentially be extracted from corpora such as this. A recent collaboration between researchers at Harvard and Google has investigated that potential for similar analyses on a much larger scale, using the 15 million book corpus developed through Google's digitisation programme (Michel et al. 2010). They have coined the term 'culturomics' to refer to these high-throughput analyses of texts and other culturally-generated data, and have particularly highlighted the potential for such studies in illuminating cultural change. Within a specific, more focused domain, such as archaeology, the potential for analysis must be considered particularly promising, given the useful baseline that can be provided by these much large datasets.
The examples given here do show that the usage of period terms varies in a non-random fashion both in the actual periods used and the number of different period terms themselves. The Roman period term was shown to dominate early articles and it is not until the 1970s that what we would recognise as the broad modern range of terms came into use. This earlier usage of a more limited set of period terms reflects the need for temporal reference points when discussing material of uncertain date. It is also clear from the simple counting of place names from the east and west of Scotland, at least in earlier volumes, that the focus of the antiquarian community was on the arable east. In addition, perhaps more prosaically, changes in administrative structures are seen reflected in the overall variety of place names used. However, the marked decrease in place name frequency at the end of the 19th century may indeed indicate a significant shift in the frame of reference for Scottish antiquarians away from the classical world towards a more self-confident assertion of a uniquely Scottish archaeology.
A superficial view of these metrics could simply serve to reinforce some of the generally assumed historical biases in the text. Without exploring the nature of these figures in tandem with the character of the language from which they are derived we couldn't expect to understand them fully. The question remains as to whether more sophisticated natural language processing might shed further light on the complex relationship between the terminology used and the meaning of the text itself, or will it only remain a starting point of more useful analysis? If it is the latter, then at least the frequency data collected as a by-product of the ADS's indexing work offers both a lever and a substantial resource to allow deeper questions to be framed.
© Internet Archaeology/Author(s)
University of York legal statements | Terms and Conditions
| File last updated: Tue Feb 22 2011