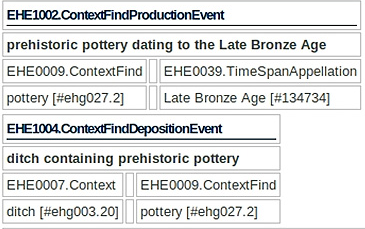
Figure 3: Example of XML annotation of grey literature report - "ditch containing prehistoric pottery dating to the Late Bronze Age"
Intellectual indexing of grey literature reports is resource intensive in terms of time and human effort and generally tends to produce relatively broad-brush metadata. Detailed CRM-based annotation has been explored as part of the Text Encoding Initiative (Ore and Eide 2009). However, unless assisted by automated tools it must be anticipated that such approaches will prove resource intensive over a large corpus. Semantic annotation, resulting from NLP-based information extraction, offers the potential to access documents at a conceptual level, mediating between unstructured text and conceptual models (Bontcheva et al. 2006).
OASIS reports currently have metadata relating to site location and archaeological unit or data provider, although in practice metadata coverage could perhaps be described as a little uneven. The data entry form also asks for metadata on notable Monuments and Finds, directing users to the web versions of EH Thesauri for Monument Types and Archaeological Objects, which can be searched or browsed online. The MIDAS Periods list allows a major monument or find to be qualified by a time period. However, the metadata exist only as text labels, without the unique identifiers that would facilitate subsequent automatic processing.
Recent work by the Archaeotools project has investigated automatic generation of metadata for OASIS reports to produce a faceted classification, in terms of What, Where, When access points (Jeffrey et al. 2009). The new version of ArchSearch builds on the results of this work, which largely employed Machine Learning techniques requiring a training set of indexed documents, along with rule-based techniques for simpler patterns such as bibliographic references. The aim of the STAR NLP work was to complement the Archeotools focus on classification by investigating the generation of more detailed, lower level, 'rich indexing' that combines different CRM-EH ontology entities in semantic phrases. These are expressed with CRM(EH) and SKOS identifiers to permit subsequent automatic processing.
The EH glossaries provided a strong core excavation vocabulary, directly relevant for STAR information extraction purposes. Selected glossaries (simple names for Deposits and Cuts, Box Index Form [Material], Box Index Form [Find Type], Small Finds Form, Bulk Finds Material List) were mapped to CRM classes (the Timelines thesaurus was used for time periods). The coverage of the glossaries was limited, lacking synonyms for example. Therefore they were expanded by drawing on intellectual mappings between glossaries and the thesauri. Various thesaurus expansion modes are currently being evaluated, including synonyms but also semantically close concepts. While evaluation is ongoing, initial results suggest that some forms of concept expansion do bring improved performance.
STAR follows a rule-based approach to information extraction, employing the GATE (General Architecture for Text Engineering) toolkit (Cunningham et al. 2002). GATE rules are realised in a cascading pipeline, which makes use of a regular expression pattern-matching engine to assist the construction of the rules, together with language processing resources, such as a Tokeniser, Sentence Splitter and Part-of-Speech tagger. The information extraction pipeline adopts a three-stage process of semantic enrichment of the OASIS reports. The initial phase pre-processes the grey literature and vocabulary resources, identifying the main sections in each OASIS report and identifying noun-phrases and verbs. The second Named Entity Recognition stage identifies CRM concepts in context using a combination of relevant SKOS thesauri and glossaries. The third stage specialises CRM annotations to CRM-EH entities, where GATE rules, developed for this purpose, find contextual evidence in the text. This generates the rich indexing of connected ontology entities.
Finally, the annotations from the GATE system are exported in XML format coupled with the source text. This is subsequently post-processed via PHP to deliver decoupled RDF files as an additional representation. Vlachidis et al. (2010) provides further background and discusses an initial exercise. Both formats, the XML files and a subset (to match the data extraction) of RDF triples, are expressed as CRM-EH and SKOS-based RDF representations of some key grey literature concepts. The RDF triples are in the same format as the extracted data, which enables cross search of excavation datasets and OASIS reports in the STAR Demonstrator.
Examples from the Demonstrator, which show search results combining data and OASIS reports, are discussed in section 3.1. The alternative XML expression shows the annotations in the context of the grey literature report, providing more associated context and a richer representation of the metadata than currently exported to the Demonstrator. Figure 3 gives an example of such rich indexing, in this case involving a context, a context find and a time period, where both CRM-EH and SKOS identifiers are shown for the indexed terms.
Figure 3: Example of XML annotation of grey literature report - "ditch containing prehistoric pottery dating to the Late Bronze Age"
The XML enhanced OASIS reports allow browsing and human inspection of the results and also subsequent automatic processing. Different retrieval strategies are possible for utilising the semantically enriched metadata in such digital libraries. For example, summary sections might be detected automatically and their metadata prioritised, as representing the main findings of a grey literature report. Alternatively, CRM entities qualified by frequency of occurrence might indicate major clusters of finds, similar to the (Archeotools) tag cloud visualisations described in Bateman and Jeffrey (2011), but with the potential of involving extracted metadata phrases. Additionally, the ability to index compound CRM annotations allows a very specific concept-based search, as illustrated in the STAR Demonstrator scenarios.
© Internet Archaeology/Author(s)
University of York legal statements | Terms and Conditions
| File last updated: Mon July 18 2011