Figure 1. Pattern of access
Internet Archaeology (IA) is an electronic archaeological journal funded entirely, so far, by eLib, the Electronic Libraries project . The eLib project's aims are to investigate the use of electronic publishing in the Higher Education sector in the UK and to promote culture change to encourage the use of the new media. A fundamental part of this project is the evaluation of its effectiveness and each eLib project has an evaluation strategy built into it. The eLib programme has adopted a scatter-gun strategy and has supported projects with a variety of approaches. Given the speed of change in recent years, both cultural and technological, this is only sensible. The use of the World Wide Web is affected by the availability of content, publicity, the cost of access and the development of the infrastructure (in which I would include both the investment in the Internet and the development of the software and hardware required to access it). The boundaries of what is possible are moving all the time, and the constraints which determined the way in which the project set out, and which were described at the CAA 1996 conference in York, may not now present such problems. For details of these constraints see the text of the paper given at the CAA 1995 Conference in Leiden/
We are particularly keen to know more about the way in which people will use the journal since we are now planning to publish papers which will not be ready for publication until 1999 or 2000. One hurdle that has to be jumped is that of funding. At present, access to the Internet is by and large free once you have selected an Internet Service Provider. If this remains the case, then there would be a strong incentive for people to publish in their own web space. If, on the other hand, the party ends and the true cost of the Internet is passed on to the end user, then IA will have to follow suit.
Unless the journal actually fulfills a function, however, all talk of its future is irrelevant. For this reason, I will spend the rest of this paper looking at the way in which the first issue of Internet Archaeology, published in September 1996, has been used in its first half-year of existence.
In order to be able to monitor access to the journal it is divided into two areas, one of which is freely accessible and the other controlled by a system of user authentication. At several points in the IA web the user is pointed towards a registration script which allows us to collect details of the user. Once this form has been filled in and returned across the Web, the user can browse the restricted parts of the journal. In the first issue this gives access to a foreword by Prof. Cunliffe, my editorial, and six papers:
The papers can be divided into those which describe a new technique or methodology: Beardah and Baxter, Gillings and Goodrick, Lyall and Powlesland; and those which are data-rich papers describing a piece of archaeological research: Peacey, Tomlinson and Hall, and Tyers. This division is also one of size. The technical papers are relatively small whereas, because of the way that data and commentary have been mixed, it is actually quite difficult to put a size on the larger research papers.
A further distinction can be made between the two groups of papers. The technical papers can be downloaded, stored on disk and read or printed off-line. There are parts of the research papers which could be read this way but the hyperlinks within them would not work off-line, and the data presentation would be lost since this is achieved mainly by the use of cgi scripts to query online databases.
Questions which immediately come to mind, therefore, include:
Clearly, the answers to these questions are of interest to all involved in the publication of archaeological research, either as producers or consumers.
Research into the use of electronic data can use several sources of information on the identity and habits of its subjects. First, we have the traditional sources, as used by print publishers and academics the world over: reviews, citations, testimonials, and word of mouth. Secondly, there are more formal and controlled sources, available to both print and electronic media, such as focus groups and questionnaires. Thirdly, and finally, we have the evidence collected on the web server through log files and the registration process. In the rest of this paper I will concentrate exclusively on this source of data, although we also collect the other forms of evidence and have carried out one formal focus group session, using students at the University of York, and will be conducting more of these formal sessions as part of the evaluation of the project.
Internet Archaeology is served through a Silicon Graphics Challenge computer running IRIX 5. The web server is WN (http://hopf.math.nwu.edu). WN's log files collect the following data for every transaction across the web:
In addition, we collect the following information as part of the registration process:
Those questions marked with an asterisk are user-supplied. The rest is supplied, unwittingly in most cases, by the browser. Since L1 should either match with R13 or R14 one would initially think that it would be possible to provide accurate figures to quantify or analyse access. In fact, linking one database to the other shows (as a moment's reflection might have told us) that for various reasons we cannot be certain that all of the log file entries for a particular address are the result of a single user's activity. On the one hand, there are people whose computer is assigned an IP address or host name dynamically on login, or who access the web from a number of computers, and on the other we have users, normally students, who share computers (e.g. in the resources room of their archaeology department). To give two examples, the highest number of hits on the journal comes from a single host computer which has been used by four individuals, whereas a search for a particularly distinctive login name (L2) showed that this individual had been assigned a different host name for every session. Given time, it is possible to look at the log file and identify individual sessions (in some cases, even being able to suggest when lunch breaks were taken). This could be automated by stipulating the interval between hits which counts as a break in session.
Once the log files can be divided up into individual sessions then further statistics would be possible (I must confess to not yet having done this analysis):
The answers to these eight questions give more than enough food for thought for those involved in the preparation and publication of material for use on the web, but there are still more possibilities once we start to use the additional data collected at registration since it is quite possible that web use varies with one's position. In theory, students have more time to read and browse whereas academics and other professionals might only look at papers they suspect contain information of use to them. Furthermore, there might be different preferences for particular papers from the various sectors that users classified themselves as belonging to. This then lead to two final questions:
We therefore have ten problems to be studied using the log file and registration data which I will now discuss in detail.
We all have personal preferences and I was expecting to find that people don't like statistics and would find clay pipe kiln construction too specialised for in-depth reading. Up to a point, the data reflect my suspicions. Taken as raw "hits" we do find that the amphoras paper by Tyers is the most popular, having received 20,701 hits up to 14th February (the end of my approximate 6 months' sample) and, as suspected, the Kernel Density paper did receive the fewest hits. However, one paper (Tyers) was available for a much longer period, since December 1995, and although any hits made before September 1996 are not counted in my sample, the fact that this paper is now present on a large number of "hotlists" and gateways may well have had an effect. When we look at the number of host computers (which I have taken as an approximation to the number of users in this case), the discrepancy between hits and hosts is not so great. Comparing the two sets of figures we see that the Hits figures, naturally enough, may be slightly inflated by the number of "pages" (i.e. separate files) into which each paper was divided. A further possible factor is that in certain papers the figures were published in separate files, with links from the text and from a list of illustrations, whilst in others the figures were deemed to be integral to the text and were sufficiently small to be included "inline".
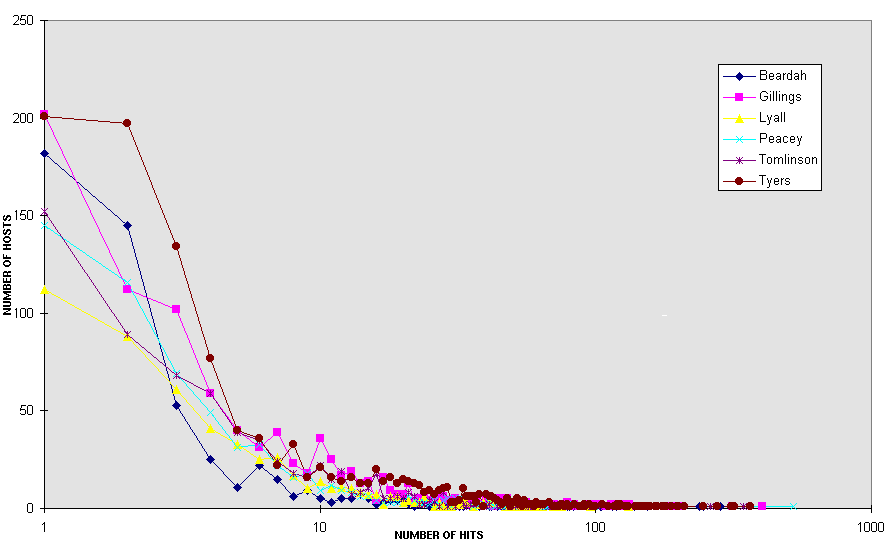
Table 1 - Which papers are popular?A further insight into the way in which the papers were being read can be gained by looking at the pattern of access. I have taken each set of hits and calculated the number of accesses per host. After all, it is possible that our total statistics were being skewed by one or two individuals who were particularly keen on the paper in question, and that everyone else was merely dipping in to the paper and then moving on. I have shown this data in the form of a log/normal graph with the number of hosts as the Y axis and the number of hits as the X axis.
We can see here that all the papers had their enthusiasts (three individuals could not get enough statistics and achieved 237, 246 and 284 hits respectively) and that the number of hosts looking at more than five pages of any paper was very limited. These figures confirm that the difference in popularity of the papers was in the main the result of intensive use by small numbers of hosts and that most users would only give four or five hits per paper.
It is important to know whether or not people read the journal on the screen or download it to read off-line since this affects the way we get our authors to write the paper. Reading on screen requires points to be put across snappily and for the entire argument to be viewed in, at most, two or three screens-worth of text. Reading off-line can either be by printing out the page or by keeping the text as HTML but having it stored on the local drive. I thought that the easiest way to test what users were doing would be to look at papers which were written so as to be read on screen (Gillings, for example) and compare the log file entries with those of a paper with longer pages (Lyall, for example, where the text is all in one file with the illustrations kept in separate files). So, I took the entries for the part 1 and part 12 of the Gillings paper to examine in detail. The first thing I found, which was a surprise to me, was that there were numerous cases where the user was downloading the first file at intervals of a minute or less during a session. It seems that in these cases the file was not cached locally and was being downloaded afresh each time the user turned back to it. Clearly, however, people were using the paper on-line. The second thing I found was that people were often not looking at both "pages" in the same session so that I could not simply work out the time elapsed between downloading the two "pages". Although it is difficult to quantify, it is nevertheless quite clear that the Gillings paper is usually read on-line, as intended. However, a similar study of the log for the Lyall paper indicates that this too was usually read on-line, with users darting from the main text to the illustrations and back again. No doubt we could find examples of systematic downloading of a paper to store off-line. In fact there is one very clear case of this where a user downloaded each page, in order, from every single paper. It seems to have taken this user over three days, working office hours, to achieve this task and even then the interactive features of the journal will not be available to the user.
Although there is room for doubt, I believe that the data here show that the papers are mainly being read on-line and this encourages me to introduce more features which only work on-line, such as the database interfaces.
We provide many hypertext links in each paper both inline, referring backwards and forwards to different sections of the paper, and at the top and bottom of the pages, in the form of a "navigation bar". It is clear from the analysis above that these are being used. In addition, each paper has a search facility which enables the user to look for single words in the text of that paper and then see the context in which these appear before jumping to the chosen link. This facility has only been used 208 times and when looking at the log files it is clear that there are certain users who always approach a paper through the search facility and the majority who never use it. In eight cases the search facility was the stimulus to register to use the journal and there is little difference in the number of instances per paper, ranging only from 35 instances for the Beardah paper to 41 for Peacey.
Figure lists were provided for five of the papers and these were much more popular than the search pages. In sixty-five cases the first protected page accessed by a new user was the list of illustrations (see Table 2, "Unregistered").
Table 2 - To what extent do people use the hypertext features we provide?These figures bear no relationship to the actual number of illustrations in the paper but the reason for the high figure for the Gillings and Lyall papers is clearly because both papers deal with graphical subjects: VRML and geophysical survey. My conclusion from this is that our users want to see what visual material there is in a paper much more than to look for a specific item.
I think that the initial analysis of the log files clearly shows that most people dip in to our papers but that when they find a subject of interest they are happy to keep on browsing, no matter what the quantity of data. There is a strong body of opinion within web publishing that the medium is suitable only for short, snappy works - the in-flight magazine of the Internet approach. Based on the access figures we have for our first six months I don't think this is a justified assertion, although it could easily become a self-fulfilling prophesy. What is important, in my view, is that each individual part of the paper is short and snappy and makes its points clearly and concisely. The fact that there might be hundreds of similar pages in the paper you are reading is not going to put people off.
Here too, I think the previous analyses actually provide a partial answer, which is that people look at the online abstracts, they look at the table of contents and the list of illustrations and then they dive in to what seems to be of interest to them. They do not, normally, start at Section One and read solidly onwards to the end. Here, I think it is a great pity we have no comparative information for the printed page, since I suspect this is also the case for most printed journals and monographs.
Rather than spend a lot of time establishing the nationality of the vast number of CompuServe account holders using the journal and those people whose host computers only send out a numerical IP address, I have simply taken two papers, one technical and the other data-rich, to illustrate that there are indeed differences in usage between the papers. The Lyall paper, for example, has been accessed mainly by UK academics and students whereas the Peacey paper is more popular with people having personal Internet accounts and with colleagues on the continent (taking Sweden and Germany as my two examples). The VRML paper, by contrast, is much more popular in the American academic domain whereas, outside of the UK, the amphoras paper is most popular in Germany. Again, this could have been predicted, but it is nice to have one's prejudices confirmed.
Table 3 - Are certain papers more international in their readership than others?The duration of sessions is clearly heavily skewed. Most are very short but some, as noted above, are effectively several days' duration.
Yes. We have numerous examples of repeated visiting to the same paper. In some cases, it is probable that the purpose of the first visit was to read the paper and in subsequent cases it was to demonstrate the contents to a third party but we have other examples where a user comes straight back to a page deep in a paper's web, either to check on its contents or as a launch point for continuing to read the paper. Naturally enough, we have no way of knowing how many of the users who downloaded a page once went on to read it or print it out. Most users of my acquaintance are not aware that the page resides on their computer (and under Windows 95 using Internet Explorer it is getting quite difficult to locate these files).
I have taken information about the readership from a copy of the registration database made at the end of our first six months online, in early February 1997, when 1596 people were registered. It may be that the proportions in different countries and sectors will vary with time. For example, looking at the figures for North America, there is clearly a higher proportion from the private sector. This is presumably both due to the fact that Internet access has extended further into the domestic and commercial world than in the UK or continental Europe and also because the topics covered in Issue One are likely to have appealed as much to people reading from interest as to people who need that information for their work.
Table 4 - What proportion of the readership belongs to each sector: number of readersThis interpretation of the data - with a progression from academic to public and private use, also fits the rest of the world, although the number of registered users elsewhere is too small to be certain. The high proportion of users in the public sector is due almost entirely to a group of ten from the Netherlands and five from Sweden. All other European countries have three or less users in the public sector. This emphasises the enviable state of public archaeology in those two countries.
Table 5 - What proportion of the readership belongs to each sector: percentage of readersTo find out whether there is a preference for different types of paper by sector I first had to relate the two data sets, losing data on the way where an IP address or hostname was not recorded in our users' database. The 28,000 hits which could be assigned to a country and sector showed that the variation in preference by country indicated in the sample used above was also visible in these figures. By sector, there were also differences, although these would have been masked if the data was not also divided by country. Thus we find, for example, that European students are keener on statistics that those in the UK (as a proportion of the total hits per country, not in absolute terms). However, they show no such preference for VRML, where the UK student sector is particularly high. Given that the paper is of practical interest, it is surprising, perhaps, to find that the Lyall paper is being read by a smaller proportion of non-academic/student readers than some of the other papers.
Table 6 - Does the preference for papers vary between sectors?It seems to me from the evidence of the log files and registration database that the users of Internet Archaeology are by and large using the pages as expected. They want to see a summary of the contents of a paper and some indication of what its scope might be, they then want to look at the illustrations and finally, if tempted, they will start to read the paper. In other words, exactly as I have seen print journals and monographs being approached by my colleagues over the years.
Our data-rich papers, all of which in Issue One were dealing with some aspect of archaeology in the British Isles, appear to appeal most to UK and continental colleagues, whereas the technical papers are more popular (outside of the UK) in America. With forthcoming data-rich papers covering the settlement of the American continent, Islamic pottery, Roman funerary monuments in Luxembourg and excavations in Beirut I expect our international audience to grow. Nevertheless, it is obvious that a geographically-specific, chronologically-specific paper will have an audience mainly composed of those people who have an interest in that topic. Each paper, then, can expect a slightly different audience and it is the job of the journal's staff and Editorial Board to see that we maintain a broad range of papers which are sufficiently interesting in their content and approach to keep people coming back to the journal.
© Internet Archaeology
http://intarch.ac.uk/journal/issue3/vince/caa97.html
Last updated: Tue Jul 1 1997