Cite this as: Huffer, D. and Graham, S. 2017 The Insta-Dead: The rhetoric of the human remains trade on Instagram, Internet Archaeology 45. https://doi.org/10.11141/ia.45.5
The amassing of human remains by private collectors of sufficient means is itself a modern microcosm of the ethical stance and practice of many American and European museums in the late 19th-early 20th centuries (see Redman 2016 for a comprehensive review). In the same way that those early collecting practices did damage and violence to communities from which the dead were collected, the emergence of social media platforms that facilitate collector communities seems to be re-playing that history. Not all of this collecting is necessarily illegal, but it is important to understand what is happening, where it is happening, and how these human remains are framed as collectable objects so that archaeologists, cultural heritage professionals, museums and so on are better equipped to engage with this desire and to channel it productively.
Understanding the online and offline trade in human remains of various categories is, relatively speaking, a new area of research (e.g. Huxley and Finnegan 2004; Kubiczek and Mellon 2004; Huffer and Chappell 2014; Huffer et al. in press). Collectors and dealers in this 'niche' market have somewhat readily garnered their own attention in the popular press, given the esoteric and macabre nature of what they seek (e.g. Davis 2015; Gambino 2016). Individuals conduct transactions while based in numerous Western and non-Western countries and actively seek 'specimens' or 'curios' ranging from former anatomical teaching specimens to mummies, 'tribal' or ancestral skulls from various cultures, Tibetan Buddhist artefacts, and even 'wet' specimens (e.g. brain slices, other organs, fetuses, or examples of gross pathology). Other recent research has begun to focus on the as-yet unassessed risk to that proportion of the global archaeological record that burial looting represents, whether done to acquire artefacts for the global antiquities trade or, at least occasionally, human remains themselves (e.g. Kinkopf and Beck 2016; O'Reilly 2007). The majority of research attempting to quantify burial looting using terrestrial survey or satellite imagery (e.g. Contreras 2010; Contreras and Brodie 2010; Lasaponara et al. 2014) usually concerns sites not actively being looted. However, several contemporary examples from 'hot-spots' such as Egypt (Popular Archaeology 2012) clearly demonstrate the threat to cemetery integrity that indiscriminate looting still poses. Other recent examples have garnered media attention owing to the rather shocking nature of the specimen being offered, the means of attempted sale, or the use to which the obtained remains were put (e.g. Killgrove 2016; McClure 2017). Only occasionally have e-commerce platforms taken action in response to exposure and public outcry (Halling and Seidemann 2016).
The ability to sell, display or trade human remains via social media and online distribution lists has led to their being treated as consumer products for a collector's market rather than objects of archaeological, ethnographic or anatomical value. To combat this practice, some state or national-level jurisdictions have introduced specific restrictions related to the sale and transport of human remains (e.g. Louisiana, Georgia and Tennessee in the United States, the UK, New Zealand, etc.), above and beyond the requirements laid upon signatories to UNESCO (1970) cultural heritage conventions, which applies to most source and demand countries. The majority of legislation concerning human remains relates to funeral home conduct or the de-accessioning of museum collections (e.g. WAC 1989; Museum Ethnographers Group 1994; DCMS 2004). Such laws have led to the unintended consequence of restricting, limiting or complicating the process of legitimate procurement of human remains for research or teaching purposes owing to a lack of uniformity and specificity in the provisions that they circumscribe (see e.g. Marsh 2016 for a summary of the various measures that some US states take to constrain the sale of skeletal human remains, beyond general adoption of Uniform Anatomical Gift Acts). The preliminary human remains market analysis research referenced above, however, clearly demonstrates that a diverse collecting community flourishes despite ongoing legal or ethical concerns of scholars or the occasional outcry from the general public. This article examines the function of this community by conducting textual analysis of thousands of posts and comments created by the human remains collecting community as it exists on the mobile-based photograph sharing application Instagram.
Despite 'terms of service' allegedly prohibiting the use of Instagram for illicit activities, numerous studies and exposés have revealed active trafficking of everything from drugs (Smith IV 2014), and guns (Goel and Isaac 2016), to exotic animals (Haslett 2015). Exploration of the frequency and scope of the trade in cultural property, let alone human remains themselves, via new social media (e.g. beyond auction house catalogues and eBay) is in its infancy or yet to be attempted. In targeting Instagram specifically, this research builds upon Huffer et al. (in press) to present the results of initial efforts to query the 'noise' of a popular platform using automated means, as opposed to very time-consuming and inherently limited manual searching. As will be demonstrated, these methods show great promise and, as we discuss in the conclusion, this work lays the foundation for several additional avenues of research.
Users often provide means of contacting them in their posts, as well as other materials that could be used to identify them. While users may post things publicly, that is not the same thing as making them available for research. The Ethics Research Board at Carleton University declared that this research was Research Ethics Exempt as per the Canadian Tri-Council Policy Statement on the Ethical Conduct for Research Involving Humans (PDF), especially with regard to Article 2.2. That is to say, the individuals posting these materials publicly via Instagram have made these articles available to the public. Nevertheless, in the version of the data that we have made available via our supporting data and code repository we have attempted to strip out usernames in the captions themselves, and we have not provided the account usernames in our table of data. We did keep this information for our actual analysis. We do provide the link to the original post and the original photograph. The only other metadata included is the user ID number, the number of likes, and the number of comments.
In recent years, network and textual analysis of social media interactions have increased exponentially, developing their own methodology and covering a wide range of topics (see for instance, in an archaeological context, Morgan and Winters 2015). Work focused specifically on mapping Instagram, however, is still rare (e.g. Highfield and Leaver 2015; Tsou and Leitner 2013; Hochman and Manovich 2013). Over the course of twelve months from November 2015 until November 2016, we queried Instagram for posts related to the buying and selling of human remains. We initially employed a variation of a 'snowball' sampling strategy, beginning at known collectors of human remains on Instagram, documented in previous research (Huffer et al. in press) ('natural selections', 'Oddmonton', 'sickeart', '_craniac_') to see what some of the common hashtags employed were. Our initial list of hashtags:
We collected several thousand photographs using Pablo Babera's 'InstaR' package (2015). This package allowed us to search Instagram by hashtag, and then to download the images and associated metadata. Unfortunately, Instagram changed the way their public API worked in June 2016 such that only those seeking to commercialise users' data could access it in this way. A second package, this one written in PHP and which automated querying and paging through Instagram's public search page (Kapishev 2016) enabled us to continue exploring these posts, although with less rich metadata (see Graham 2016). Instagram's own help pages suggest that their search function will return all posts with a particular hashtag, so while it is ultimately impossible to tell, we feel that we have collected a representative sample of at least the last three years' worth of posts connected with this trade.
An example post by user 'natural selections':
'This is a real 1900s, turn of the century, medical prep human skull! skull belonged to an Adolescent female from India. It was supplied by University of Cambridge to a medical student. The jaw and skullcap are hinged and can be removed as desired. can ship this specimen worldwide, anywhere human osteology is legal. We're asking $1200CAD(~900USD), buy it now on […] Toronto (Saturday-Sunday 12-6pm).'
https://www.instagram.com/p/BM4MrAEAiqa
In the year that we took to collect data, Instagram grew from 400 to 600 million users (Instagram 2016). We initially collected some 20,000 posts and rows of data. While the snowball approach enabled us to collect a rich corpus of materials to analyse, cursory paging through the images showed that we were collecting materials far removed from our target. There is, for instance, a thriving community for buying and selling taxidermy, and this trade overlaps with antiques and antiques, and with knick-knacks more generally. Human remains are to be found this way, but not efficiently. We returned to the data and asked a different question:
If we assume that a person new to the community wanting to buy or sell human remains will explicitly use the '#humanskulls' or '#humanbones' hashtag, what will they find on Instagram? What does Instagram look like from that perspective?
This provided us with a much clearer signal of what this bone trade on Instagram can look like. We collated the 'humanskulls' and 'humanbones' posts for a total of 13,410 individual posts. It is important to note that we are not producing 'the answer' or a definitive discussion on this material; rather, the use of these digital humanities tools and approaches allows us to create deformations of the materials that highlight different trends within it (that is to say, we read against the grain in a way to both perform and deform an understanding of the materials, often via computational means; see Samuels and McGann 1999; Ramsay 2011). We are setting the scene for further questions and investigations, while also highlighting the need for further development and use of tools to curate, query and analyse popular social media platforms in order to understand licit and illicit e-commerce and collecting subcultures more thoroughly.
Our data, analytical scripts, and figures may be found in the repository (Huffer and Graham 2017).
We filtered the captions on each post for numerals and indicators of value such as $. There were twenty-two unique accounts that named a price. Then, we worked through each post to determine what was for sale, and its likelihood of being actual bone rather than a replica (we discuss the language of the captions further below). We do not necessarily know where a vendor is located. While the metadata captured with the InstaR package returned latitude and longitude values, it seems the vast majority of users have geolocation turned off on their devices. In what follows, we do not analyse location data and have expunged those columns from the dataset as we are not exploring in this article the legality of this trade, which is dependent on jurisdiction. As it happens, there are approximately 1400 posts with the tags or phrases 'for sale', 'sold', 'sell', 'purchase', or 'forsale' where dollar figures are not listed, e.g.:
'I have a pile of teeny human skull scraps laying around. Due to etsys rules i cannot sell human bone or make a listing but id love to do custom orders for anyone interested in a pendant, ring, etc made from a human skull fragment. Dm me! #bone #bones #skull #humanbone #humanskull #fragment #skullfragment #oddities #oddity.'
https://www.instagram.com/p/znHyR7AbXS/
We collected posts listing items being sold, which in total amounted to approximately $190,000 (including items listed in GBP or EUR, converted to USD) over the four years from 2013-2016.
In posts that listed prices in USD (2016 dollars) only, we found:
indicating a fairly steep growth in this trade or, perhaps more likely, a willingness to actually name prices in the open. While these amounts are not as large as found in the trade in other kinds of antiquities, they are not insignificant. These amounts are approximate, because sometimes it is not clear just how many items are for sale at a given price, or whether a given item appears in multiple posts. Even visual inspection of the images is not always sufficient to determine this. Where there was doubt, we always assumed the minimum.
The data are in the file 'humanbonesandhumanskulls.csv' (Huffer and Graham 2017).
The typical post contains a certain amount of text mixed together with a long tail of hashtags. We can count the words and tags within the posts, and compare these against the 'normal' distribution of words in the English language (as evidenced by the Trillion Word Corpus compiled by Brants and Franz 2006 and further processed by Norvig 2008, and made available in R as the file word_frequency.csv by Arnold and Tilton 2017). We filter out the common day-to-day words (that have a high frequency in the Trillion Word Corpus) and end up with the most common words in this corpus of Instagram posts that are otherwise uncommon in day-to-day English (see 'simple_counts.r', which is based on Arnold and Tilton's tutorial in The Programming Historian 2017). We copied the captions into a new file, where we pre-processed to convert everything to lowercase. Thus, we get a sense of what this community speaks about most often:
word count:
By contrast, without the comparison to the Trillion Word Corpus, the top words are:
This is a great deal less illuminating, containing largely common stop words ('a', 'and', 'of', 'to', 'in') and variations on the second word in our original search term, 'human skull'. Stop words, in computing, are words filtered out before or after processing of natural language data (text) (Rajaraman and Ullman 2011). By balancing out the count of words against the Trillion Word Corpus, a clear pattern emerges. We can see that this community frames their engagement with human remains as an experience with the 'other' - skulls and human remains are objects valued primarily for their ability to invoke the thrill of owning something taboo. The words 'taxidermy', 'goth', 'handpainted', 'crafty' point to another interesting pattern in this corpus: the reuse of human (and, clearly, animal) remains for 'artistic' reworking, as well as other forms of art inspired by bone motifs.
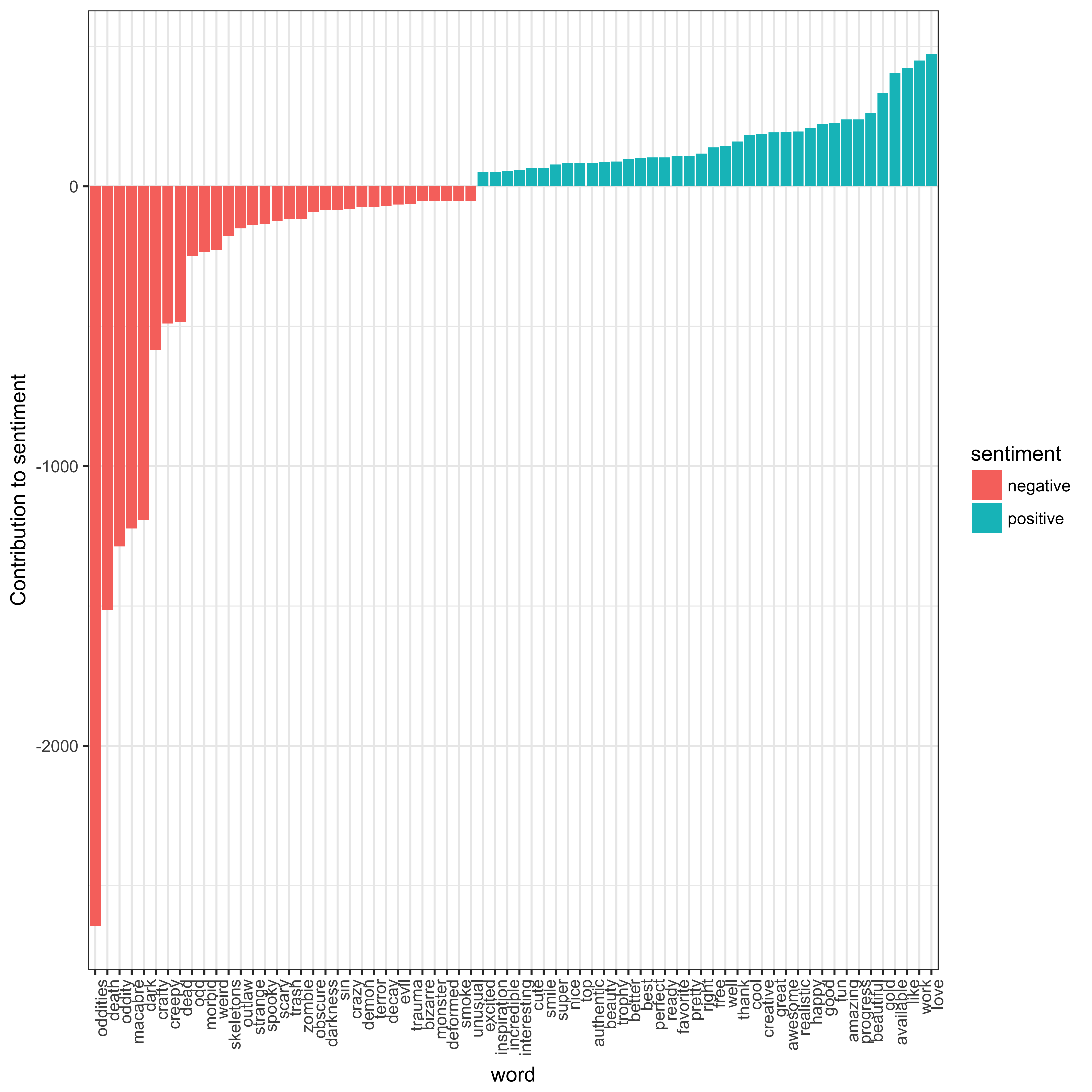
In recent years, companies such as NetBase and Radian6 have created lexicons that may be used to assign a 'sentiment' to the words found in social media (all the better to target advertising) (Financial Times nd). One such, the Bing lexicon, may be invoked in R via the 'tidytext' package (Silge and Robinson 2016). We can classify the words used in these posts as 'positive' and 'negative', and see what the resulting pattern may suggest (Fig. 1). (We use here our complete corpus of human bone captions, rather than the subset filtered against the Trillion Word Corpus discussed above.)
| word | count |
|---|---|
| death | 1514 |
| oddity | 1287 |
| horror | 951 |
| mortality | 603 |
| black | 445 |
| vampire | 401 |
| rebel | 378 |
| witch | 335 |
| morbid | 236 |
| weird | 227 |
'oddities', 'death', 'oddity', 'macabre' contribute the most on the negative side, while 'love', 'work', 'like', 'available' contribute the most on the positive side. In this particular corpus, the Bing lexicon is leading us astray, because 'oddities' are not discussed in negative terms – rather, the more creepy, macabre, or dark, the better. The positive words on the other hand seem to be part of the dialogue among creators as they make their art.
Another lexicon, the NRC Emotion Lexicon (again, available through the tidytext package) gives slightly different results (Tables 1 and 2).
Here, an interesting aspect is the concern with authenticity: 'real', 'medical', 'antique'. In many jurisdictions, the sale or shipping of human remains falls within a legal grey area, hence the desire to assure that remains are real but medical or Victorian antiques, which has the effect of removing them from the world of human bodies into the world of simple objects that may be bought and sold (e.g. Nessen 2012). The overlap of this world with the 'art' world is reflected in the leading prominence of 'art', but also the word 'progress', which points to the many photos individuals share of their work underway. It's not about the finished object but rather the process.
| word | count |
|---|---|
| art | 3220 |
| real | 691 |
| medical | 625 |
| antique | 539 |
| curiosity | 505 |
| love | 473 |
| gold | 334 |
| sculpture | 268 |
| beautiful | 262 |
| progress | 239 |
We can delve deeper into the language of the posts by considering the relationships of the words via a word vector, or rather, a word embedding, model. In this approach, the idea is to ask, 'what if we could model all relationships between words as spatial ones?' (Schmidt 2015a; 2015b). That is to say, we create a linear ordering of all words so that words that are used most similarly are closely spaced. While there are a number of approaches to doing this, in general they try to model similarities of word use between words as distances in this space, and that the relationships between words will have similar paths - vectors - along this space. Schmidt helpfully contrasts these 'word embedding models' with the better known 'topic models' - if topic models help impose order on documents by boiling them down to 'topics' of a few words, word embedding models ignore the individual documents so that one can understand the way all the words are being used. They are complementary approaches.
The analyses for this section were performed using the script, 'wordvectorscaptions.r'. Again, we copied the captions to a new file where we pre-processed the text to remove all special characters. We left numerals in. Finally, the use of emoji in posts can lead to strange 'words' like 'ude4c'; in this case, this is the code for two hands raised in celebration. Should the reader encounter such codes, a quick online search of the code will remove confusion.
Once the word embeddings model was created, Schmidt's package (2015b) allowed us to explore the vector space around a word, or group of words. For instance, we note that 'notforsale' appears in many Instagram posts. When we retrieved the words closest to 'notforsale':
nearest_to(model,model[["notforsale"]])
we got:
which suggested that signalling something is 'not for sale' might not necessarily mean what it appears to mean. Conversely, when we looked at 'for sale':
nearest_to(model,model[["forsale"]])
we got:
We visualised the relative positioning of the words most closely associated with 'for sale' and 'not for sale' using the following code snippet:
some_groups = nearest_to(model,model[[c("forsale","nfs","notforsale")]],50) plot(filter_to_rownames(model,names(some_groups)))
This code reduces the vector space to two dimensions using 't-Distributed Stochastic Neighbor Embedding', a kind of clustering technique (van der Maaten and Hinton 2008).
The resulting graph should be read by considering the distance of a term depicted on it to our anchors of 'forsale', 'nfs', and 'notforsale' (Fig. 2). A word like 'oddity' and its variants seems to fall more or less equidistant from these anchor terms, while something like 'antiquebones' or 'personal collection' might be signalling the potential for a sale. We can also observe elements that make bones more collectable or desirable: medical specimens, patinas, deformities.
Another perspective can be generated by taking the vector along the 'for sale' to 'not for sale' binary and mapping how another binary pair maps against this; a technique suggested in Ben Schmidt's follow-up post on the language of RateMyProf posts with positive/negative language against male/female (Schmidt 2015c). In our case, it's not clear at the outset what the second binary pair should be, so let us compare forsale/notforsale against positive/negative language (Fig. 3). In this case, we're not using the top words tagged with the sentiment analysis as 'positive' or 'negative', but rather the words 'good' and 'bad'.
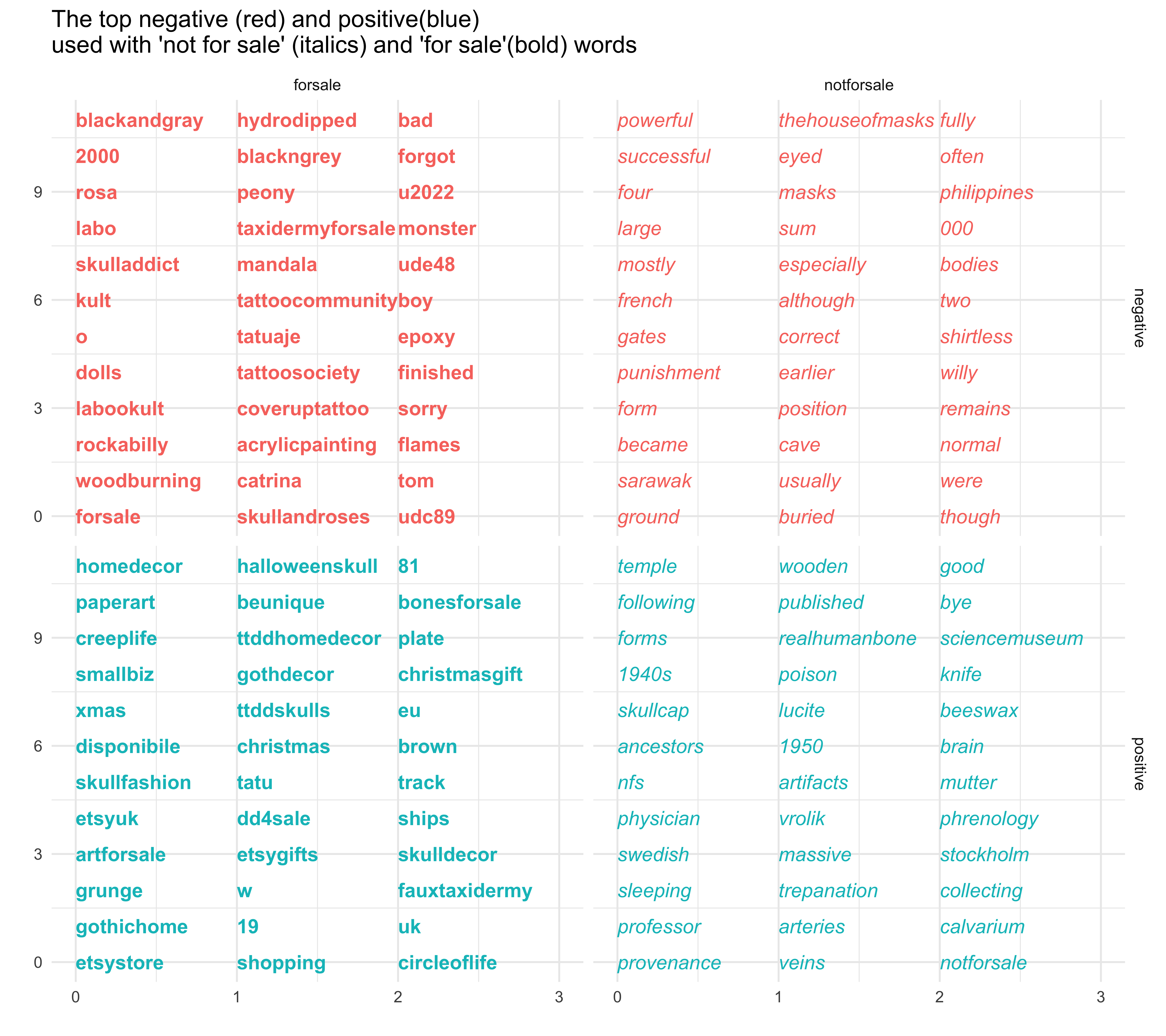
In the 'forsale' column, many of the words in the 'positive' row are words connected with the online store for handmade crafts, Etsy. Also prominent are words connected to moving those remains around ('ships', as in to transport). The word 'gifts' reveals one marketing tactic, as in, 'makes perfect christmas gifts' [sic]. The Christmas 2016 marketing push seems quite prominent as well. In words associated with the 'negative' column are many words demonstrating the close affinity of this community with tattooing. It may be that the word we used to construct the negative end of the positive-negative vector, 'bad', is being used among the tattooist subcommunity here as its very antonym. In the not for sale column are words signalling academic authority or jargon. Given that 'notforsale' is a word associated closely with 'antiquesforsale', is it an indication of 'for sale at a price I won't name publicly but it is clearly extremely valuable'?
We can ask to what degree are the participants in this community aware of legal norms or repercussions of trading in human remains, by defining a vector around the words 'law', 'legal', and 'ownership'. [1] 'event' [2] '900' [3] 'buyskulls' [4] 'desired' [5] 'ownership' [6] 'geriatric' [7] 'pelvic' [8] 'asking' [9] 'local' [10] 'additional'
The interested reader can use our script to explore these vectors for herself by substituting words of interest into the code. The scripts will break if the reader runs it on words that do not exist in the corpus, so check first by substituting the word of interest like so:
nearest_to(model,model[["your-word-of-interest-here"]])
and running that line. If R returns 'n/a' then your word is not in the corpus.
We can use topic models to impose some structure on these captions using the 'topicmodels' package for R (Grün and Hornik 2017). A topic model is a way of extracting semantic structure from a body of text, where we model what these topics or discourses might look like if there were only ten (or 20, or 50, or 100… etc.) topics from which ideas were generated. It is a statistical analysis of the patterns of co-occurrence of words over the entire distribution of words in the corpus, by document. Here, the 'documents' are each individual post. Thus, we end up with a mathematical breakdown of the composition of each post by topics. One post might be mostly topic 4 – for instance – with a smattering of topic 2. What the topics mean requires the interpretation of the investigator (for technical discussion of what topic modelling is and how to do it, see Brett 2012; Graham et al. 2012; 2015; for an example in an archaeological context, see Mickel 2016). The exact number of topics to fit cannot be a priori determined with the script we used (which you may inspect, topic-models-mallet.R). Instead, we generate a number of models and explore differing numbers of topics to work out which model seems to capture and separate out the variety. In our case, 25 topics seems to work well:
Note the close association of topics clearly connected with buying and selling, and topics related to trophy skulls and other indigenous ethnographic materials. While a post might not necessarily mention a trophy skull being bought and sold, the patterns of discourse are very similar. These materials are not being discussed with respect, but as commodities. As we progress to the right in the dendrogram, we see other topics connected with the mechanics of the trade - giveaways, a gift for christmas, hallowee'en. If we take one commercial trader in antiques in general ('234396855'), we can also visualise the patterns in the posts. Authenticity is always the key for this trader; giveaways of bone seem to be a loss-leader, perhaps.
Finally, it is interesting to note that there is a topic that might be thought of as relating to tourism - topic 25 (Fig. 5). While many people share pictures from the catacombs of Paris (and elsewhere) they do not seem to use the same descriptive tags as individuals interested in collecting bones. Indeed, topic 25 seems roughly to be the dividing line between people who are interested in skulls and bones as a motif/inspiration for their art, and for those who wish to possess the dead.
What kind of audience do the most popular accounts that are openly selling human remains have? How is it structured? The topic modelling above seemed to imply a roughly tripartite division in the interests motivating the use of the 'humanskull','humanbone' tags on Instagram. In what follows, we make an initial foray into a network analysis of this trade, noting that this is only an attempt at outlining the scale and scope of this network.
Ideally, one would systematically obtain the list of followers for each and every user account (the 'seed') in our corpus. Then, we would obtain the list of followers of followers, and then delete the original user accounts so that this initial seed did not unduly affect the results. As an initial experiment, we instead took the twenty-two accounts that named a price, and obtained the lists of followers (current as of 7 December 2016, using https://webrobots.io/scrape-instagram-followers/) for those twenty-two. This gave us a network with 138,014 individuals connected by 172,208 links. We do not provide this file since the vast majority of accounts in this network are not directly targeted in this study; rather they provide a proxy here to indicate influence and impact of the individuals whose materials we did collect.
We converted this network so that we had the network of twenty-two accounts connected by the follower they had in common using the multi-modal transformation plugin for Gephi; the weight of the connection thus represents the number of followers the two accounts had in common. The resulting file is accounts-openly-selling-connected-by-followers-in-common.graphml. We then queried the graph for community structure. The result was three distinct communities. In Figure 6, the individual accounts are sorted left to right by those distinct communities; within those groups the accounts are ordered by pagerank, or the likelihood that a random wanderer in this graph would end up at that account (we produced the arc plot with the script arcdiagram.R). The first group (users 1, 14, 15, 19, 20) is what we might call the specialists, that is, accounts explicitly selling mostly bones. The second (users 2, 3, 4, 5, 9, and 22) are the generalists that seem to have a much wider variety of materials than just bone. Finally we have the enthusiasts (users 8 onwards), that is, users who for the most part enjoy looking at pictures of human remains. The present analysis cannot be pushed any further than this, and the topic as a whole awaits further investigation. We gesture towards it only for the sake of completeness of the present study. While twenty-two accounts may not sound like very much, the reach and impact that they may have (over 100,000 unique accounts) is vast.

Literary scholars and historians have devised methods to explore the reuse or subtle alteration and reprinting of texts across corpuses (e.g. Cordell et al. 2012-2014; Beals 2017; Funk and Mullen 2016). Are there patterns of text reuse in this corpus? And if so, what does that signify?
We used Lincoln Mullen's R package 'textreuse' (2016; suggested use-cases are discussed in Mullen 2015) to explore this question (see textreuse.R in the repository). In essence, the package compares each document with every other document (based on ngrams of 5, that is, sequences of five words at a time) and calculates a jaccard coefficient of similarity. In our case, 13,410 documents so compared would result in 89,907,345 unique comparisons. The advantage of Mullen's package is that it uses computational shortcuts (via a process of 'hashing') to reduce the number of comparisons to be made. In our case, the package identified 3438 posts that used the same snippets of 5gram text.
A score of '1' indicates a perfect match. We found several hundred posts scoring 1. This was not an error: in every case, the post is a unique post with a unique photograph yet using the exact same caption in its entirety. People selling this material or discussing this material use the same language time and time again. For example, take this post:
'Real human skull for sale, message me for more info. #skull #skulls #skullforsale #humanskull #humanskullforsale #realhumanskull #realhumanskullforsale #curio #curiosity.'
There are a number of posts by this user, using the exact same caption (and which the textreuse package scored at '1'. A post at .9375 similarity has one extra hashtag appended to the text (and, of course, a different photo):
'Real human skull for sale, message me for more info. #skull #skulls #skullforsale #humanskull #humanskullforsale #realhumanskull #realhumanskullforsale #curio #curiosity #dead.'
We continue on until we are at around .5 for our score:
'Skull and arm £400 for the pair. One of the fingers on the hand is missing its tip and the whole arm needs glue removing and tidying up a bit. Real human skull for sale, message me for more info. #skull #skulls #skullforsale #humanskull #humanskullforsale #realhumanskull #realhumanskullforsale #curio #curiosity #dead.'
That one phrase, 'Real human skull for sale, message me for more info', and that sequence of hashtags seems to be as good an identifier for this individual as any username. Indeed, we find through general web searching of that sequence of hashtags that this particular individual is cross-posting to Facebook as well and thus proves a salutary reminder that what is facilitated on one social network likely propagates across multiple ones.
We can consider the posts by another user, who makes art out of what are claimed to be resin-cast skulls.
CRAIN #slaughterskulls #skulls #skull #humanskull #bones #crafty #dark #macabre #art #artwork #handpainted #oneofakind #strangegirl #mortality #death #skullart #custom #oddity #oddities #curiosities #scarylady #aprilslaughter
scores 1 with:
#CRAIN #slaughterskulls #skulls #skull #humanskull #bones #crafty #dark #macabre #art #artwork #handpainted #oneofakind #strangegirl #mortality #death #skullart #custom #oddity #oddities #curiosities #scarylady #aprilslaughter
and scores .9 with:
#BLUESTAHLI #slaughterskulls #skulls #skull #humanskull #bones #crafty #dark #macabre #art #artwork #handpainted #oneofakind #strangegirl #mortality #death #skullart #custom #oddity #oddities #curiosities #scarylady #aprilslaughter
If we look further down the list, to weaker scores (0.33), we still see that the textreuse is the sequence of hashtags:
It would seem that the U.S. Forest Service doesn't enjoy my work. Nor do they appreciatemy traipsing around the mountainside taking photos of it. I did it anyway. #slaughterskulls #skulls #skull #humanskull #bones #crafty #dark #macabre #art #artwork #handpainted #oneofakind #strangegirl #mortality #death #skullart #custom #oddity #oddities #curiosities #scarylady #darkart #darkdecor #aprilslaughter.'
Finally, we can see a fan of this user uses the exact same sequence of hashtags (the score on this post is 0.22), a strategy to ensure that the post is seen by other fans (N.B., the @ handles have been removed by us):
'How cool is this skull by @USER_NAME_HERE? Go check out her account and give her a follow. She's holding an awesome giveaway that I'd love to win. Fingers crossed!********************************** @USER_NAME_HERE from @USER_NAME_HERE - It's this time again. Good luck! @USER_NAME_HERE. Winner will be chosen at random and skull will be made and shipped in July. #slaughterskulls #skulls #skull #humanskull #bones #crafty #dark #macabre #art #artwork #handpainted #oneofakind #strangegirl #mortality #death #skullart #custom #oddity #oddities #curiosities #scarylady #darkart #darkdecor #horror #aprilslaughter #giveaway #Regrann.'
We could look then in the scoring of the weakest similarities to find fans or others co-opting a particular sequence of hashtags. The patterning of hashtags and the reuse of sequences of tags seems, on this reading, to be a sign of influence between users or a sign of community, a marker of imagined connection between users.
Placing so many hashtags into a post is also a kind of search-engine optimisation technique known as 'hashtag stuffing'. Actually typing so many tags over and over again on a phone or tablet is difficult, and so we are probably also looking at text shortcuts and expansion to make the process easier and more consistent. Hashtag stuffing is the social media equivalent of 'Keyword stuffing', or the practice of loading the metadata of a webpage with keywords in an effort to distort the search results for that page, making it appear higher on the page. On Instagram, there is a limit of 30 hashtags allowed (https://help.instagram.com/351460621611097; although we have examples where there are more than 30 hashtags, which may mean that the '30' rule has only recently been instituted. Figure 7 presents the histogram of hashtag counts by posts. At least one social media marketing firm suggests that 11 hashtags per post is the optimum number for fostering engagement, where 'engagement' is defined as 'interactions'; presumably this means clicks on the hashtag, or being surfaced in a search (Harris 2013).
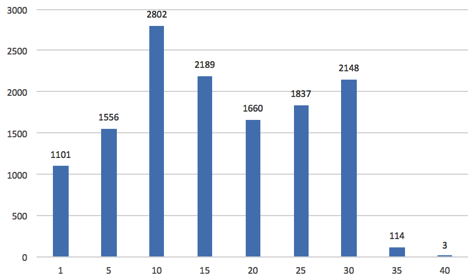
The precise mix of hashtags, then, might be seen as a signal to identify particular communities or subcommunities. In any event, it appears that a substantial number of users making posts here are savvy enough in the conventions of the platform to ensure that their posts are being seen.
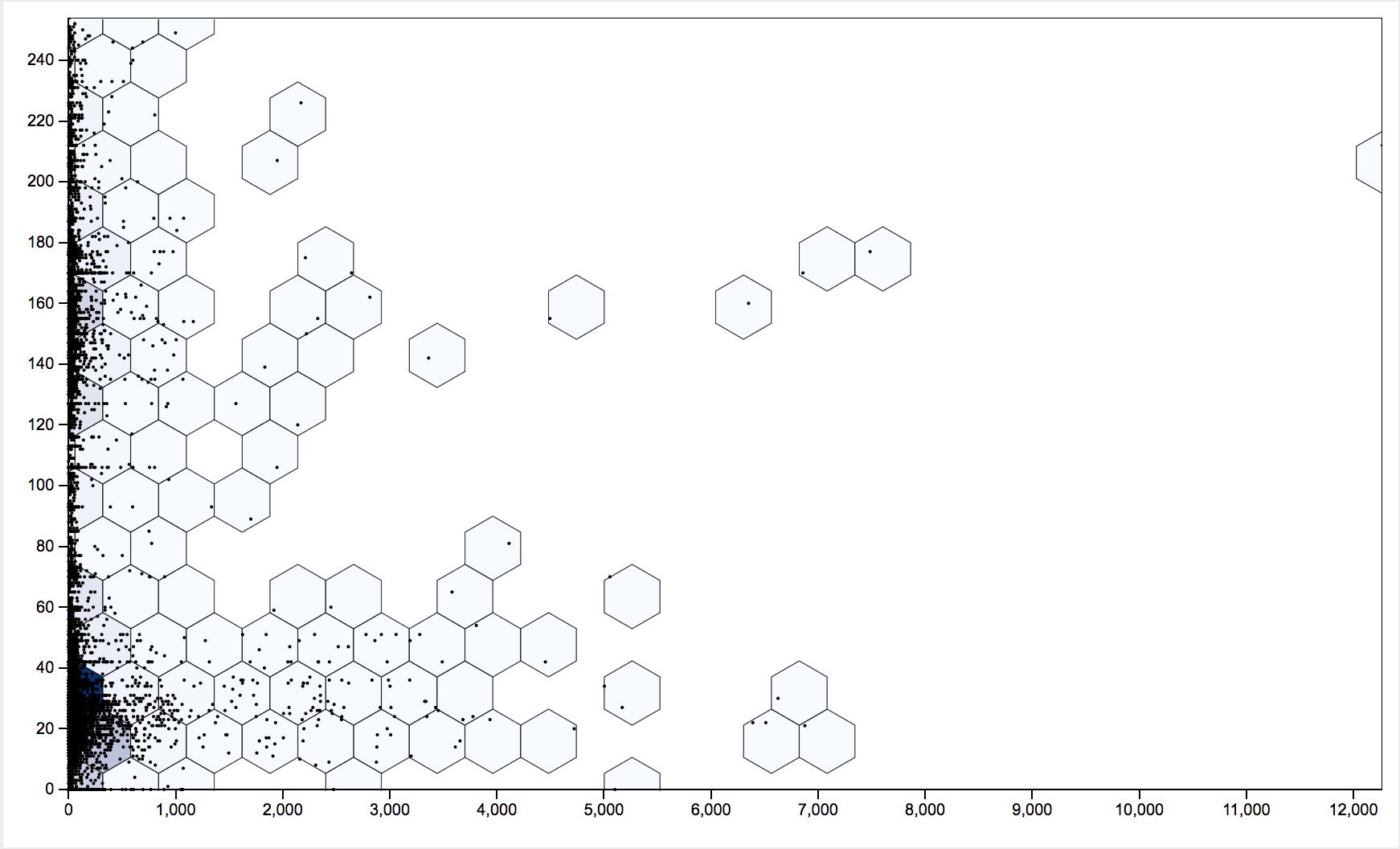
In a follow-up paper, we intend to perform large-scale image analysis to explore patterns in the 'visual grammar' of these photographs, mapped against the patterns drawn out from this 'distant reading' of the corpus. On 20-22 January 2017, we attempted to save a copy of every photograph from every post we had collected. While we had the URLs for 13,410 images, only 11,639 could be downloaded, meaning 1771 had either been marked 'private' in the interval or had been deleted. These photographs were then analysed using the ImagePlot macros (Ushizima et al. 2012; SoftwareStudies nd) devised for the ImageJ photographic analysis software. ImagePlot can analyse photographs by hue, colour, and saturation as well as by counts of contiguous 'shapes' (areas of similar colour defined by hard lines). Future work will investigate whether or not we can plot images by their shape count compared against the number of hashtags, better revealing within the photos those 'assemblages' unique to specific collectors, or collectors sharing geographic location or interests. Figure 8 shows an initial plot of hue (vertical axis) against the number of likes (horizontal axis) that on first glance seems to show some sort of relationship, which may point to some kind of visual grammar at work. Our initial experiments with the pastec.io image recognition API (Maglo 2014) may also point to the emergence of a kind of similarity in how these photographs are composed, or indeed the reposting and re-appropriating of others' photographs (Baumann 2015, on the reuse of images in the Rijksmuseum).
The data presented above, together with Huffer et al. (in press), form the foundation of a new long-term (multi-year) study of this overlooked and unique category of cultural property trading specifically using new social medial such as Instagram. The methods detailed above can be used by any scholar seeking a better understanding of the intricacies of supply and exchange within the particular social network under study, and especially if aspects of it are buried beneath multiple layers of 'noise' (i.e. randomness in social media metadata). For those seeking to re-create research such as the above on other social-media mediated collecting networks (whether cultural property or not), readers can access certain aspects of our raw data and scripts from the github repository (Huffer and Graham 2017). In a broader sense, our results suggest that the trade in human remains is more multifaceted than expected when using manual data mining methods alone. Investigating patterns of content creation and sharing, as well as larger issues of network structure, advertising, gender relations, etc., on Instagram through tailored search algorithms is relatively novel (e.g. Highfield and Leaver 2015; Zhang et al. 2016; Hosseinmardi et al. 2015; Cavazos-Regh et al. 2016). Research such as the above adds to the oeuvre of 'Instagram studies' in its own right and markedly expands what we can know about the practice of this collecting community where most of the commercial activity seems to take place.
To summarise and reflect on our observations from the extent of our analyses to date, and remembering that our initial question was what does Instagram look like from the perspective of one searching 'humanskulls' or 'humanbones':
Given that this approach to investigating the human remains trade, or any aspect of the cultural property/antiquities trade on Instagram, is novel, new research directions and an ever-expanding textual and visual corpus will provide more detailed insights into assemblage creation and community advertising and sales practices. In addition to the photographic analysis research mentioned above, we intend to investigate the ways modern-day collection of human remains is itself a microcosm of the ethical stance and practice of many American and European museums in the late 19th-early 20th centuries, and the implications (Redman 2016).
In a recent article, Hamilakis (2017) discusses a novel way to conceive of assemblages in archaeology, whether in practice (e.g. how to interpret material evidence for communal feasting), or theoretically. Specifically, he defines an assemblage as 'a temporary and deliberate heterogeneous arrangement of material and immaterial elements', and further suggests that to interpret an assemblage of artefacts (whether at an archaeological site or in a collector's living room), one must consider 'affectivity, memory and multi-temporality' (Hamilakis 2017). Current evidence suggests that human remains collections are an ideal example of an assemblage as defined above, and the high degree of connectivity seen between the most active collectors identified so far would guarantee that each individual's assemblage at any one time is 'temporary'. Whether or not the information conveyed in each transfer of ownership (by word of mouth or whatever written records exist) is accurate seems at least occasionally to be irrelevant. As reported elsewhere (Huffer and Chappell 2014), one online dealer stressed on their website that it's 'the story that sells the skeleton'.
It is our wish that research of this nature will expand, not only with regard to cultural property and the antiquities trade, but also in relation to the ability to use text mining, neural network analysis and machine learning as tools to incorporate visual and quantitative data directly into automated data mining of social media so as to search, sort and make connections more effectively. The research presented above is fundamental to these efforts, as our collaborative study of the use of 'new' social media to move cultural property, and of the dynamics of the human remains trade itself, continues in coming years. We expect that the ultimate picture that develops regarding Instagram will be far more complicated than what we have seen already, and so we offer the present study as a data point for the future.
Internet Archaeology is an open access journal based in the Department of Archaeology, University of York. Except where otherwise noted, content from this work may be used under the terms of the Creative Commons Attribution 3.0 (CC BY) Unported licence, which permits unrestricted use, distribution, and reproduction in any medium, provided that attribution to the author(s), the title of the work, the Internet Archaeology journal and the relevant URL/DOI are given.
Terms and Conditions | Legal Statements | Privacy Policy | Cookies Policy | Citing Internet Archaeology
Internet Archaeology content is preserved for the long term with the Archaeology Data Service (ROR). Help sustain and support open access publication by donating to our Open Access Archaeology Fund.