Cite this as: Batist, Z. and Roe, J. 2024 Open Archaeology, Open Source? Collaborative practices in an emerging community of archaeological software engineers, Internet Archaeology 67. https://doi.org/10.11141/ia.67.13
A 2012 special issue of World Archaeology marked the coming of age of 'open archaeology', a new, digitally orientated archaeology 'predicated on promoting open redistribution and access to the data, processes and syntheses generated within the archaeological domain 'with the aim of 'maximizing transparency, reuse and engagement while maintaining professional probity' (Beck and Neylon 2012, 480-81), situated within the wider open science movement. In the same issue, Ducke (2012) specifically drew attention to software -- the programs and other operating information used by a computer to analyse archaeological information -- calling on archaeologists to more actively engage in open-source practices - making software with source code available for anyone to freely access, modify or reuse. Open source, though originating outside academia, emerged as an important component of and complement to open science, sharing its vision for a communal, self-correcting and transparent mode of knowledge production. Where before archaeologists had relied almost exclusively on 'hand-me-down' software repurposed from other fields (Scollar 1999), open archaeology envisaged a community of archaeological research software engineers orientated around open-source development practices and tools.
More than decade on, we are in a position to ask whether this hopeful early rhetoric of open archaeology has been borne out in actually existing open-source research software engineering in the field. Does academic open source actually make research processes more transparent and improve research outcomes? Is it actually boosting efficiency by establishing a common store of knowledge and productive code? Is it actually helping to foster new globe-spanning connections and lead to novel research trajectories that would not otherwise come to pass? In other words, is there more to 'open archaeology' than just uploading text files to the internet?
The aspirations of open archaeology's early proponents (e.g. Kansa et al. 2014; Kintigh et al. 2015) were tempered by notes of caution that 'the reward structures in academic and professional archaeology do little to incentivise participation in Open Archaeology' (Lake 2012, 475, echoing Beck and Neylon 2012; Kansa and Whitcher Kansa 2012; Huggett 2012; Limp et al. 2011). Following recent work by Nguyễn and Rampin (2022), Pownall et al. (2023) and Leonelli (2023), we believe that the outcomes listed above indeed only arise in contexts where there are organisation structures, governance strategies, and professional norms that encourage them. Thus practical circumstances and systemic value regimes that frame what it means to work as an archaeologist presently inhibit the potential for radical transformation, even among open science's most ardent supporters.
There is no question that archaeologists are prolific software developers (Batist and Roe 2023). But beyond simply making their code available on the web, do archaeologists also implement social strategies to advance open-source ideals? Does archaeological open source actually help achieve greater transparency, sustainability, and community participation? And if not, what does it actually achieve?
This article presents a survey of open-source archaeological software development with two goals in mind:
We use quantitative analysis to consider how archaeological software development may be benefiting from, or missing out on, the affordances that open-source development models provide, specifically the value added through working as part of a broader community of invested stakeholders, processes of iterative improvement, and increased code transparency. As such, our work examines whether archaeologists are harnessing the collaborative potential that the open science movement ascribes to the use of open source software and resources.
Academic open source has a complicated relationship with open source as practised by professional software developers, which has its own distinct history and is framed by different objectives, challenges, and value regimes. Despite this, the open science movement, within which open archaeology emerged, draws direct inspiration from open source. For instance, the Open Knowledge Foundation (2015) publishes a widely accepted definition of 'open' in the context of scholarly communication that explicitly refers to the definition of 'open source' published by the Open Source Initiative (2007), an authoritative open-source advocacy group. The open science movement further mimics open source by operationalising scholarly communication through technical infrastructures and protocols that closely resemble systems and processes designed to develop open-source software (e.g., the use of plain text, line-resolution version control, emphasis on formal licencing, the general hacker aesthetic). However, academic work, including the development of academic software, differs significantly from the work involved in massive open-source projects that literally run the internet, such as the Linux kernel, openSSL and the Firefox web browser. While they may use similar tools and technical protocols to manage coding operations, the open science and open source movements are governed by different social and professional warrants and interests. In other words, publishing code openly on the web has different meanings, impacts and implications for archaeologists and professional software developers (Ratto 2007; Kelty 2008, chap. 9).
Open source is a software development model that prioritises transparent work processes. Initially driven by the idea that computer users should be free to understand and manipulate the software that they install on their computers (e.g., 'free software', as initially conceived by the Free Software Foundation), open source has become a means of collaborative software development (Kelty 2008, chap. 3, especially page 99 onwards). By putting one's code on the web without restriction on how it may be used or manipulated, this encourages creativity to flourish as people contribute to help improve the code base. Software thus emerges from the coordinated labour of worldwide volunteers, who shape the product according to the collective vision. An open code base may also be used to support alternative projects whose missions diverge from the original plan, and an entire project may be 'forked', or taken in a new direction if contributors are dissatisfied with how core developers run things.
Open source has traditionally been referred to as being based on meritocratic principles (Raymond 1999, 39). A good test of whether a contribution should be included in a published software release is whether it is functional (Kelty 2008, 220). Moreover, with more eyes looking over a code base it is easier to identify flaws with a contribution, and flag potential bugs or security issues (Raymond 1999, 27-30). This is all done in the spirit of producing functional code, and in ideal circumstances faulty contributions will be corrected before inclusion. Personal ego is minimised in favour of co-creating stable and functional outcomes (Raymond 1999, 39-41).
However, this is not the same as saying that open source is completely anarchic or based on the 'wisdom of crowds'. In fact, successful open-source projects incorporate complex organisational structures, governance strategies, and forms of social mediation to help delegate and vet contributions made by distributed participants (O 'Neil 2009). They rely on, rather than eschew, institutional support structures, in order to motivate work, keep volunteer maintainers involved, and generally ensure that the project can be sustained over the long term. Open source is more than just putting your code online; to be successful, it requires participation in a social experience (Ratto 2003; Kelty 2008).
In other words, as with many so-called 'soft skills' that are crucial for academic professional development, additional competencies relating to the maintenance, management, and distribution of software, such as the ability to receive and implement feedback, set and stick with long-term goals, coordinate labour, document work practices, and collaborate with others, are grossly under-appreciated factors that contribute to an open-source project's success.
We therefore consider open source to be a means of collaboration more than a means of transmitting information. It involves developing software as part of a group, developing consensus, and working with common purpose. Crucially, it also involves having a welcoming attitude, a sense of humility, and an understanding that one's work may be appropriated and used in unanticipated ways.
The open science movement comprises a series of practices and principles intended to make research more accessible, transparent, and efficient. Although the concept of 'open' is somewhat nebulous in terms of its abstract definition and with regard to what real-world applications count as being open, one commonly cited definition describes content that 'can be freely used, modified, and shared by anyone for any purpose' (Open Knowledge Foundation 2015). This definition does not state what open is for, how to be open, or any sort of social or discursive framing behind the open movement. However, most open science advocates (including archaeologists, as exemplified by Beck and Neylon (2012) and Marwick et al. (2017)) claim that they are motivated by a desire to facilitate novel research opportunities, make participation in scientific research more equitable, reclaim science as a public good, and enhance how findings are validated and legitimised.
The idea that scientists should generally contribute to a public domain of knowledge without profit motive has led to open science being heralded as revolutionary, community orientated, and anti-capitalist means of production. However, while open science does have the potential to effect radical change, this is not a given. The social and institutional contexts in which we do science is firmly embedded within capitalist and neoliberal power structures that reward individualistic competition and do little to actually encourage equitable and accessible research practices, and as such, make it difficult to fully embrace open science ideals (Mirowski 2018). Moreover, the open science movement, which is dominated by STEM disciplines, prioritises a grossly simplified and asocial notion of what science is and entails. Namely, it considers science as the accumulation and assembly of a species-level understanding of the world, which is not held by any one individual but is stored in seemingly value-neutral and disembodied media, facts and observations. This is manifested by information and communication technologies that host files, document processes, facilitate co-working opportunities, and perform automated processes (e.g. digital repositories, reproducible notebooks, automated evaluation of research findings, systems for ensuring stable references to consistent identifiers, etc.).
This culminates in an obsessive concern with digital workflows pertaining to legal and logistical issues; for many proponents of open science, publishing is largely considered the business of typesetting and copyright law, which could be rendered moot by using automated publishing workflows and by encouraging use of open licensing agreements (cf. Foster and Deardorff 2017; Harnad 1998). Viewed as merely technical systems, these could be resolved through technical means. However academic publishing and ownership involve social arrangements that serve to stabilise knowledge, grant authority to validated claims, and enable science to move forward (Kelty et al. 2008: 274-275). In other words, technocentric visions of publication workflows tend to ignore the fact that publication is a cultural phenomenon, whereby projects are made complete and knowledge claims are articulated, credited, and rendered accountable to the people who proposed them. However, technological systems have become so emblematic of open science that the use of these tools and resources designed to support open science is often mistaken for actually doing open science (Leonelli 2023, 23-24).
Open science is typically compared with the open-source movement in that they both involve a distributed, digitally mediated and worldwide labour force, who somehow derive rough consensus directed towards assets held in the public domain (Tennant et al. 2020). But they differ in terms of the contexts in which they operate, the stakeholders involved, and the kinds of outcomes they produce. Whereas open source emerged from concerns over consumer rights and then developed as a means of maintaining resilient and collectively motivated projects, open science is driven by a warrant to make research practices more transparent and accessible. Open source is performed by professional and hobbyist software developers alike, and participants contribute in a wide variety of ways (including: programming, writing documentation, translating software and documentation, bug reporting, and financial support), but, in open science, scientists are usually the only participants actively involved in creating and maintaining contributions.1 Moreover, whereas open source projects often attract participants with varied stakes in the software and use cases in mind, open science projects are typically bounded by small communities of specialists with very particular needs (Kling et al. 2003). Additionally, open science is bounded by the professional contexts in which science operates and, as such, produces outputs that can be easily credited to specific sets of individuals for reasons of resumé-building, tenure and promotion (Mirowski 2018; Dorta-González et al. 2021). Open science projects whose contributions are supported by research funding also face sustainability concerns, as participants lose motivation to contribute once funding runs out (Carver et al. 2022; Adema and Moore 2021). Once a project is completed, papers have been published, and credit has been allocated, it is common for scientists to mark their projects as finished and move on to new endeavours (Kelty 2008, 271-75; Howison and Herbsleb 2013). Scientists may archive their work in an institutional repository, at which point the work enters a stasis state that invites reference to the completed work, but which precludes any potential for the work to be updated, modified, or directly built upon. Open-source projects, on the other hand, are motivated by a more practical need for the software to function properly in perpetuity, and contributors may remain actively or sporadically involved to satisfy users' needs, or to direct users to derivative and functional forks of abandoned software (Kelty 2008, 278-81; Coleman 2012, 116-22; Hippel and Krogh 2003).
The adoption of open-source development models among archaeologists is generally informed by the broader open science movement. However, the predominant concern with implementing best tools to use, adopting optimal data processing pipelines, and tying into global, web-based infrastructures, protocols and standards (cf. Kansa et al. 2014; Kintigh et al. 2015; Roosevelt et al. 2015) distract from fundamental tensions and contradictions regarding the actual value of working in the open. For instance, Faniel et al. (2013, 299-301), Atici et al. (2013, 676-77), Huggett (2018; 2022), Sobotkova (2018), Opitz et al. (2021), Hacıgüzeller et al. (2021), and Batist (2023) demonstrate that to make the reuse of archaeological data feasible and useful in a practical sense, it is necessary to re-introduce social friction that these infrastructures are designed to eliminate. In other words, the pressures and circumstances of being an archaeologist and doing archaeological research - such as the inherent subjectivities involved in characterising finds, or the reliance on analysts' reputation and academic pedigree to establish trust in the data they produce - assert themselves when attempting to make practical use of these infrastructures, and therefore must be accounted for in their design and implementation. In this article we draw attention to similar sources of dissonance with regard to the promise, potential, and actual implementation of open-source software development models among archaeologists by analysing the collaborative milieu in which archaeological software are actually being built and relating our findings to broader observations about how archaeologists tend to collaborate in practice.
Open source is an inherently internet-based development model and is supported by technical infrastructures that facilitate global distribution of labour and code. Here we provide a brief overview of key technologies that archaeologists have come to rely on as they develop open-source software. See Table 1 for a glossary of the git-, GitHub- and software engineering-related terminology which we use here and throughout this article.
| Term | Definition |
|---|---|
| CodeBerg | Open source alternative to GitHub |
| Comment |
On GitHub, text post attached to an issue, including the first one that describes the issue |
| Commit | Set of changes (addition, alteration, or deletion) to files in a repository that has been recorded by git as one entry in its log |
| Commit access | Ability to make changes to a repository directly, without making a pull request |
| Contributor | User that has made at least one commit to a specified repository |
| Follow | Add activity by another user to a user's timeline |
| Forge | Web-based platform for hosting, distributing and facilitating collaboration on version-controlled computer code, e.g. GitHub, GitLab, Codeberg |
| Fork | Copy of a repository owned by another user; forking is a prerequisite to making a pull request |
| git | Open source version control software |
| GitHub | Commercial platform that freely hosts git repositories and provides extended collaboration and social networking features, such as pull requests, issues and stars |
| GitLab | Open source alternative to GitHub |
| Issue | Feature of GitHub that records and tracks a bug report, feature request or other suggestion in a repository |
| Maintainer | Individual that has overall control of a repository, generally assumed to be its primary contributor. Repositories can have multiple users with commit access in addition to the maintainer |
| Merge | Accept a pull request and incorporate its changes into a repository |
| Organisation | Entity representing a group of users, which can also own repositories |
| Pull request | Mechanism by which users that don 't have commit access to a repository can contribute to it. The repository's maintainer or another user with commit access must decide whether to merge (accept) the changes, or decline them |
| Repository | Individual project that uses git for version control. Can include a mix of different types of files |
| Star | GitHub's version of a 'like', applied by users to a repository |
| Timeline | Chronological feed of GitHub activity from repositories a user has starred and other users they follow. Also includes repositories that a user is not following if they are 'trending' or determined relevant by GitHub's algorithm |
| User | On GitHub, an individual with an account that can own repositories |
| Version control | System for tracking changes (additions, alterations, or deletions) in a set of files, typically but not exclusively computer code |
Chief among these is git, a protocol designed to facilitate open and distributed contributions to a common code base. It operates by providing mechanisms for synchronising communal, web-based public repositories with local iterations stored on contributors' private workstations. Contributors who volunteer or are assigned to develop, inspect, or revise a specific aspect of a code base download a copy of the public repository into their own work environment, create a fork in which they apply their modifications, and then request that their fork be merged into the central code base. After a public repository's maintainers decide to merge the proposed changes into the communal code base, other developers may use git to download these changes while keeping their own independent forks intact.
Git is also designed to facilitate code review and version control. All modifications are tracked as 'diffs', which highlight additions or deletions to the code base, including changes within individual files. Typically, a contributor will group a series of changes into a more comprehensive 'commit' based on a specific task or part of a workflow. Commits are always accompanied by a message, in which the contributor (ideally) describes the reason and context for the changes included in the commit. Moreover, git assigns each commit a unique identifier and identifies the contributor by name and email address to ensure some degree of public accountability.
Software forges - collaborative web platforms like GitHub, GitLab and Codeberg - are designed to facilitate open-source software development by hosting public git repositories. However, they also support common software developer and project management practices, such as issue and bug tracking, code-commenting, task management, identity and permissions management, web publishing, vulnerability detection, creation and maintenance of metadata, and financial sponsorship.2 These platforms also implement standard social media functions, like the ability to follow projects and individual users to receive updates on their activities, 'star' certain repositories as a combined bookmarking and 'like' feature, and maintain a public-facing profile that includes personally identifying information (e.g. profile picture, username, real name, employer or affiliation), references to all public activity on the platform, and links to the user's other social media profiles. Code-sharing platforms thus serve as comprehensive developer portfolios and community networking resources. While these additional features are meant to complement and enhance the experience of contributing to open-source projects, they are not actually part of the git protocol.
As a concrete example of how git and GitHub is used by archaeologists, we can take https://open-archaeo.info itself. The website at that address was at the time of writing generated from a git source repository containing the data on the individual entries, a set of HTML templates, and some R scripts that translate between them. A copy of this repository can be downloaded and worked on locally by anyone, who will have access not just to the current state of the source code but its full history through the git version control software. The authoritative version is hosted on GitHub at https://github.com/zackbatist/open-archaeo. The GitHub URL indicates the primary maintainer of the repository, 'zackbatist' - that is, one of us (ZB) - who created and has ultimate control over it. However, various other contributors (such as JR) have added entries, corrected entries, or added functionality to the website using the fork and pull request features of GitHub. The basic unit of this type of contribution is the commit, which is a discrete set of changes (e.g. adding an entry) associated with one contributor at a single point of time. Others have contributed by raising issues describing problems with or suggestions for the project, leaving comments on these issues, or more loosely by using GitHub's social media features (stars and following). The full history of all these types of contributions to open-archaeo can be accessed through GitHub - or, as we use here, its programmatic API. This basic workflow is the same whether the project in question is a document like open-archaeo, or a piece of software, or a research paper; though actual patterns of collaboration vary markedly, as we will see.
We present an exploratory quantitative analysis of open-archaeo (Batist and Roe 2023), a directory of 493 pieces of open-source archaeological software and other digital resources maintained primarily by one of us (ZB) since 2018.
We compiled the dataset by browsing collaborative software development platforms, relying heavily on their social networking features. More specifically, we update open-archaeo by manually crawling through archaeologists' profiles on these platforms, as well as on other personal, professional, and institutional websites that describe and host additional archaeological software. We supplement this quasi-systematic collection strategy with word-of-mouth contributions made by interested individuals, who reached out via email, social media or at conferences to identify relevant work that we initially overlooked, including work that they created themselves.
Open-archaeo is a relatively comprehensive list. While our initial intention was to only list open-source software, its scope has expanded to include all software created by and for archaeologists. Apart from regular updates by its primary maintainer (ZB), it has been expanded by a wider network of contributors and has benefited from the wider range of domain specialisms this has brought. However, open-archaeo generally lacks software written before archaeologists started using collaborative software development platforms such as GitHub, and software that is not shared on the web at all. It also includes numerous non-software resources, as well as software developed and distributed without the use of software forges. Open-archaeo is also limited by the experiences of its primary maintainers, which affects the dataset's overall scope and how comprehensively it covers various domains of archaeological research. 3
| Host | n | % |
|---|---|---|
| GitHub | 410 | 83.0% |
| Codeberg | 16 | 3.2% |
| GitLab | 6 | 1.2% |
| Bitbucket | 1 | 0.2% |
| Launchpad | 1 | 0.2% |
| None | 60 | 12.1% |
Where applicable, we obtained more detailed information about each repository's contents and contribution histories from the GitHub API (application programming interface). Our analysis incorporates data on 407 repositories,4 145548 commits, 1920 issues/pull requests, and 22303 comments from 561 distinct users, as well as repository metadata on programming languages used, licensing, stars and forks, and so on.
We opted to collect repository data only from GitHub because it is the most popular forge platform used by open-archaeo projects (Table 2). This means that we excluded projects that do not use version control (12% of the total) or that develop and host code on platforms other than GitHub (5% of the total) from the parts of the analysis that examine how archaeologists develop software. However, we were still able to draw from all records to ascertain the general composition of open-archaeo, and by extension, to address what kinds of software and resources archaeologists make.
That being said, we cannot account for practices that occur through offline or private channels, or forms of collaboration we do not know about. We did not directly observe or interview archaeological software developers, though our conclusions do draw heavily from our experience as members of that community ourselves. 5 Our earliest data are from 2005 and our study can say little about collaborative software development in archaeology before this point, though we know there was a significant amount of it (Ducke 2013; Whallon 1972).
These caveats notwithstanding, the open-archaeo directory and the supplemental data from the GitHub API provide a rich resource to explore the nature of collaborative software engineering in archaeology. Here we employ exploratory data analysis (sensu Tukey 1977) to identify and describe overall patterns visible in this rich dataset. In Section 4, our focus is on examining the general state of open-source archaeological software and resource development. In Section 5, we refine our analysis to examine development processes, with specific focus on collaborative experiences. Finally, in Section 6, we apply network analysis methods to investigate the formation of broader collaborative communities. Our analyses combine to support our objectives of understanding what kinds of software and resources archaeologists are making, how they create these tools in response to specific needs and use-cases, and how this work is situated within the context of an emerging community of practice.
The quantitative analyses and figures presented here were generated with R version 4.3.1 (2023-06-16) (R Core Team 2023). The full data and code are available in the compendium that accompanies this article (Roe and Batist 2024).
As of writing, open-archaeo catalogues 493 resources created by and for archaeologists. It includes both software and documents, but not research compendiums (collections of digital resources, including data, code, and documentation, which accompany or enhance a scientific publication; see https://research-compendium.science.).6 Each record in open-archaeo is assigned to a category based on how the tool or resource is meant to be accessed or used, and is annotated with tags that describe what aspect of archaeological research each item was meant to address. Tags are ascribed based on how developers identified their projects' purpose and scope, and each record can have multiple tags. See Batist and Roe (2023) for a more comprehensive overview of the tags and categories applied to open-archaeo.
| Category | Scope | n | % |
|---|---|---|---|
| Software | |||
| Packages and libraries | Sets of functions assembled with clear purpose, and made accessible using standards established by an underlying platform. | 223 | 45% |
| Standalone software | Software that may be operated without needing to first access an underlying platform. | 71 | 14% |
| Scripts | Sets of pragmatically assembled mutable functions, often lacking complete documentation or adherence to protocols that would otherwise facilitate secondary use outside their original contexts of creation. | 65 | 13% |
| Documents | |||
| Lists and datasets | A series of consistently organised observations assembled with purpose. | 76 | 15% |
| Guides | An educational resource or documented protocol meant to instruct readers how to apply relevant tools or techniques. | 29 | 6% |
| Products | Stable outcomes of creative work. | 15 | 3% |
| Specifications, protocols and schemas | A formal data structure or framework intended to be used as a model. | 14 | 3% |
From our breakdown of open-archaeo by category (see Table 3), we can infer the prevalence of various development models, and the requisite technical capabilities that developers assume users hold. Most resources (45%) included in open-archaeo are designed to be used with an existing 'platform' - for example a package that extends a programming language (e.g. radiocarbon calibration is implemented in R in the package 'rcarbon' or Python in the package 'iosacal ') or a plugin for an application (e.g. 'ArchaeoAstroInsight' adds tools for measuring astronomical alignments to QGIS). Essentially such projects create additional functions within the base platform that are useful for archaeological purposes. Others create standalone software (14%) that can be run independently of such platforms, for example desktop or web apps. A significant number of projects also comprise datasets (15%) and non-packaged code snippets (13%) that have been made available for general use.
| Platform | n | p |
|---|---|---|
| R | 200 | 68.5% |
| Python | 43 | 14.7% |
| QGIS | 15 | 5.1% |
| Mobile app | 7 | 2.4% |
| MATLAB | 6 | 2.1% |
| ArcGIS | 3 | 1.0% |
| LibreOffice Calc | 3 | 1.0% |
| Microsoft Excel | 3 | 1.0% |
| Blender | 2 | 0.7% |
| Open Data Kit | 2 | 0.7% |
| Other | 8 | 2.7% |
Some 41% of all projects are extensions to the statistical programming language R, making it the most widely used platform by a large margin (Table 4). Python, another programming language, is also relatively popular (9%), as are plugins for the open source geographic information system QGIS (3%).7 Beyond that, there is a rather fragmented landscape of plugins for other desktop software (e.g. AutoCAD, ArcGIS), a number of lesser used programming languages, and a genre consisting of custom forms and spreadsheet templates. Many of these are targeted by only one or two developers; the larger platforms tend to be more diverse.
At first glance, the relative popularity of R versus Python is perhaps surprising; Python is regularly ranked as the most popular programming language in the world, with R a distant runner-up. However, it accords with the popularity of R as a tool for data analysis in archaeology (Schmidt and Marwick 2020) and other scientific disciplines (Lai et al. 2019).
Our analysis of thematic tags highlights aspects of archaeological work that software developers are inclined to contribute to (Table 5). The most common themes are work that naturally benefits from advanced information processing afforded by computers, such as statistical analysis, sample calibration, geographical analysis, data management, and chronological modelling. Educational resources and practical guides are also well represented owing to the web's usefulness as a medium for sharing and communication.
When we compare categories with thematic tags, we see the general domains that each kind of resource is designed to serve. We see that packages are fairly common across the board. Tags that are notable for having a higher proportion of standalone software include archaeogenetics, data management, 3D modelling, photogrammetry, drivers and IO, and simulations or agent based modelling. These tools may require greater access to system resources, or may require more complex user interfaces than what R or Python IDEs (integrated development environments) tend to provide.
To enact their mandate of ensuring that anyone can access and modify software and other creative works, the open source and open science movements encourage developers and scientists to adopt open licenses. Licenses are legally binding statements that stipulate how a creative work can be accessed and used. Proprietary licenses usually require explicit permission to be granted so that the work can be accessed or modified, usually in exchange for financial compensation. Open licenses, on the other hand, are more permissive, and allow anyone to use creative works without such harsh restrictions. While it is certainly possible to write your own license, it is very common to simply use one of several standardised open licenses (see choosealicense.com). Some licenses, like GNU, MIT and Apache, are explicitly suited for distributing software, and specify certain use cases that are afforded by digital media. Other licenses, like the Creative Commons variants, are more suited to other kinds of creative works such as books, articles, movies, music, photographs, and websites. The Creative Commons licenses also include clauses that cater to academic or creative sensibilities, such as requirements to attribute credit to the original authors, to restrict commercial use, and to propagate similar restrictions in derivative works.
| License | n | % |
|---|---|---|
| None detected | 245 | 49.7% |
| GPL | 123 | 24.9% |
| MIT | 77 | 15.6% |
| CC0 | 12 | 2.4% |
| CC-BY | 8 | 1.6% |
| Apache | 7 | 1.4% |
| AGPL | 5 | 1.0% |
| Unlicensed | 4 | 0.8% |
| CC-BY-NC-SA | 3 | 0.6% |
| CC-BY-SA | 3 | 0.6% |
| CECILL | 2 | 0.4% |
| BSD-3-Clause | 1 | 0.2% |
| GFDL | 1 | 0.2% |
| MPL | 1 | 0.2% |
| ODbL | 1 | 0.2% |
Roughly half of open-archaeo repositories are accompanied by an explicit license (Table 6). Two common free software licenses account for the majority of repositories that do contain licenses: the GNU General Public License (GPL, 52%) and the MIT License (31%). These differ primarily in the restrictions they place on reuse: the MIT License aims to be maximally permissive, while the GPL is a 'copyleft' license specifying that all derivative works must be distributed under similar terms (in other words, it prohibits the use of open-source software within non-open software (Dusollier 2007). Interestingly, archaeologists' preference for the more restrictive of these two licenses is the reverse of the general trend seen in open-source projects on GitHub (Balter 2015). Creative Commons licenses are a distant third place (10% of repositories), in contrast to their widespread use for other forms of scholarly output (Kim 2007). Many repositories do not specify a license; given a documented misconception among academics that GitHub can serve as a sustainable and long-term code and data hosting platform (Milliken et al. 2021; Escamilla et al. 2022; 2023), it is possible that many maintainers whose work is included in open-archaeo similarly assumed that making their work available, without explicitly stating permissible use, is enough to allow unrestricted access to the repository's contents. However, we cannot verify this potential explanation given the methods we currently employ, and more discursive qualitative research is needed to explore the rationales behind such decisions.
Archaeological software development activity has increased significantly over the years. Figure 1 shows the cumulative growth of code contributions committed and pushed to GitHub repositories, and the number of GitHub repositories that host archaeological software and resources.
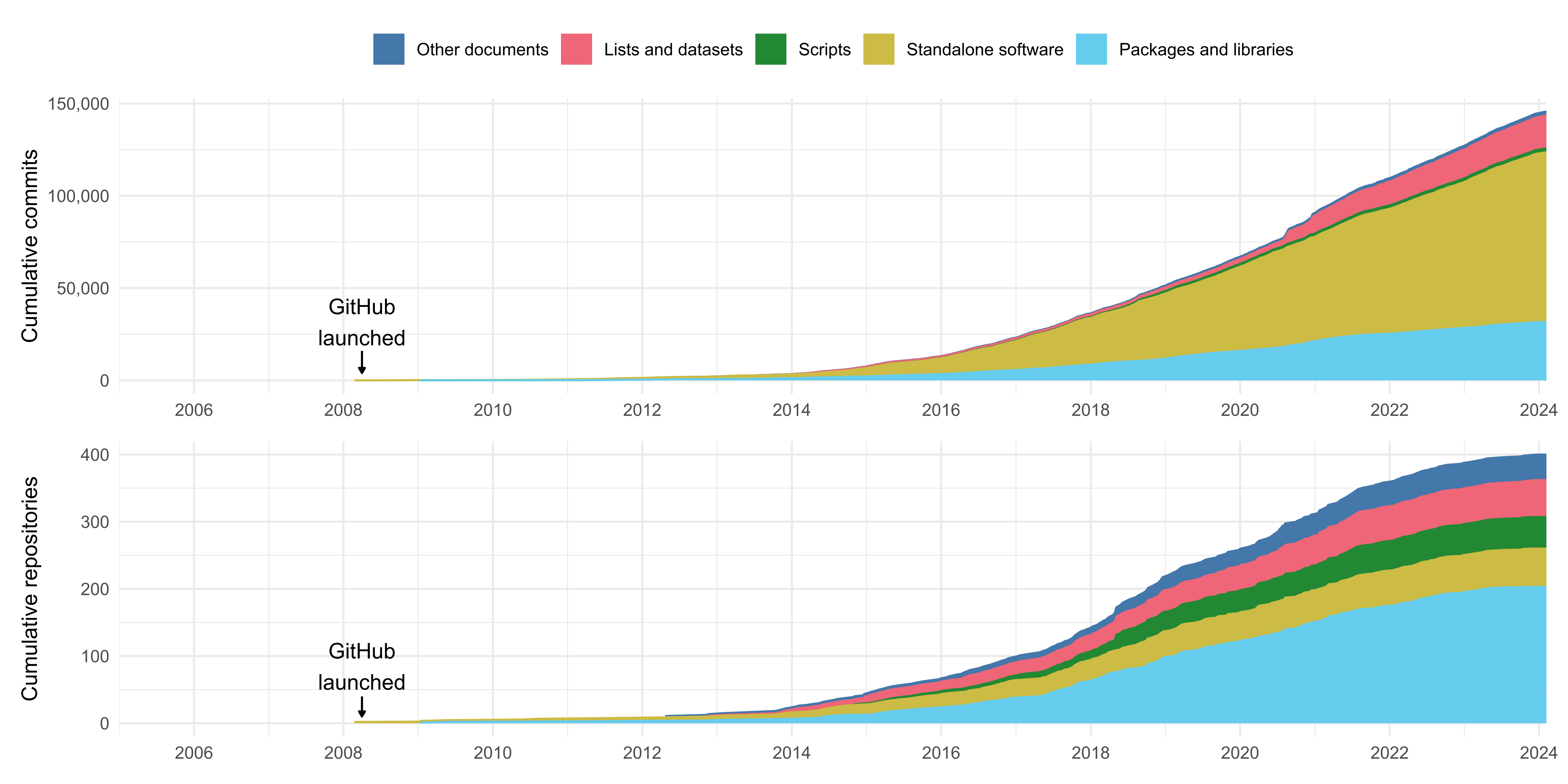
Archaeologists have been using git from at least the late 2000s, shortly after GitHub was launched,8 but it saw a marked increase in popularity c. 2014-2015. From that point and until recently there was an exponential uptake of GitHub by archaeologists, but while we were preparing this article (c. 2022) the first signs of a slowdown in growth have appeared, with the number of cumulative commits continuing to rise but the number of repositories hitting a sharp plateau. This could be explained by market exhaustion, a shift in emphasis to maintaining existing code and working on established projects, and/or growing doubts about the appropriateness and sustainability of GitHub following its acquisition by Microsoft (Kansa 2022). 9
GitHub's entry into the digital archaeology mainstream in 2014-2015 also marks the point at which we see it being used for things other than packaged source code (e.g. documents and scripts). This suggests that the 'early adopters' of GitHub, pre-2014, were more directly embedded in existing (open source) software development communities, while those that came later also saw version control systems as a potential medium for dissemination and archiving. It may also reflect a general move towards git- and GitHub-based workflows by archaeologists attracted to open, participatory, and/or generally 'nerdy' academic practices.
As well as hosting source code, GitHub and other software forges include systems for facilitating collaboration on code and other projects. The basic collaborative workflow is inherited from git, which allows multiple users to commit code to the repository (see Table 1 for definitions of this and other git terminology used in this section). A user with commit access to a repository can change any of its contents at will, so this is usually reserved for the project maintainer and known, trusted, collaborators. GitHub extends this model with its pull request feature, by which any user can fork a repository to which they don 't have commit access, make changes, then offer to contribute those changes back to the original repository. The maintainer can choose to merge (accept) or decline the pull request, facilitating contributions from a wider network of collaborators without the need for permission to be sought in advance.
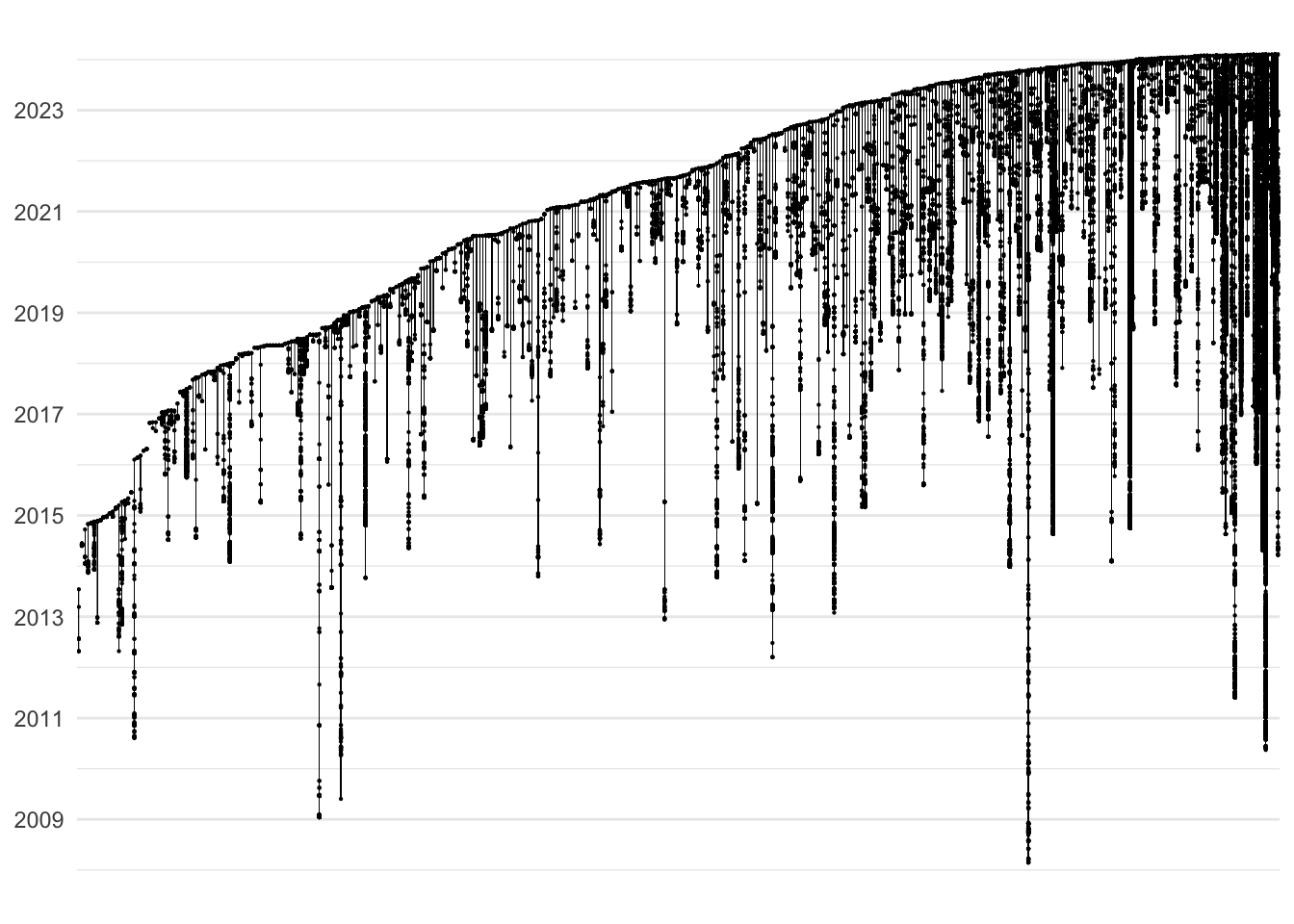
We measured the lifespan of a repository as the time between the first and latest commit, and its activity as the number of commits per day. Here, therefore, we refer to the development lifespan of a project, which is not necessarily related to its use-life. By these metrics, the lifespan and activity of repositories in open-archaeo vary greatly (Figure 2). The average project lasts 920 days with 0.76 commits per day. Many projects are active for only a short period of time: about 17% less than 30 days, 26% less than 90 days, and 38% less than a year. However, the vast majority (all but three) do have more than one commit, suggesting that use of GitHub as a pure host for already finished projects is not common; some degree of iteration, if not collaboration, is almost always present. The longest-lived projects have been active for between 10 and 17 years. The most active projects see up to 13 commits per day, but the majority of repositories (84%) receive less than one commit per day.
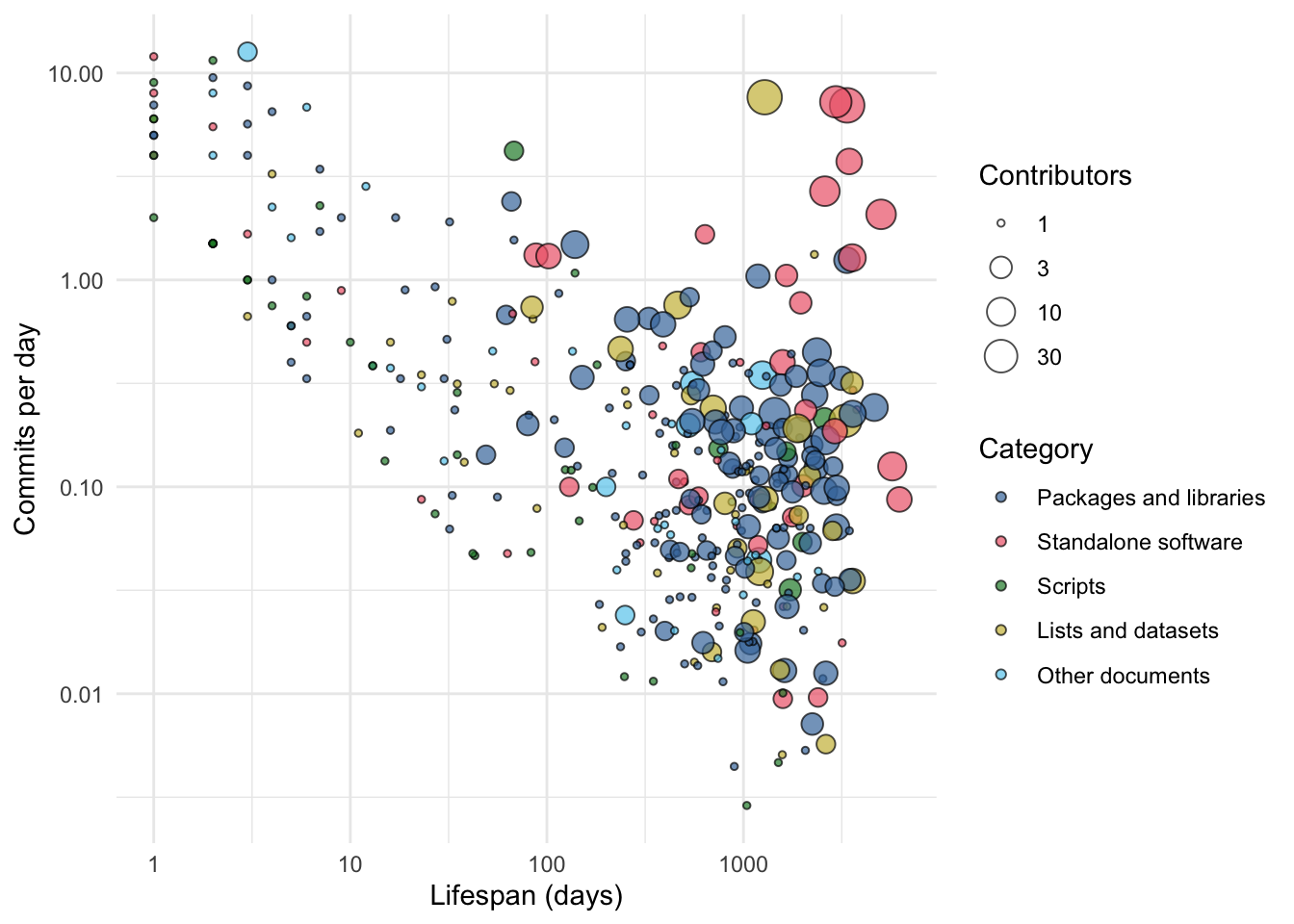
The interaction between project longevity, activity, and number of contributors is multifaceted (Figure 3). Highly active projects (one commit per day or more) tend to be either very long-lived or very short-lived; few fall in the centre of the distribution. Short-lived projects tend to be characterised by a 'spree' of activity (a high commit rate), while long-lived projects have a broader range of activity profiles. The most 'successful' projects according to open-source norms (i.e. long-lived and active) are, with few exceptions, those projects with the largest contributor base in our dataset. However, the modal project in the centre of the distribution is more modest, lasting around three years, maintained by an individual or a small group, with around three commits per month.
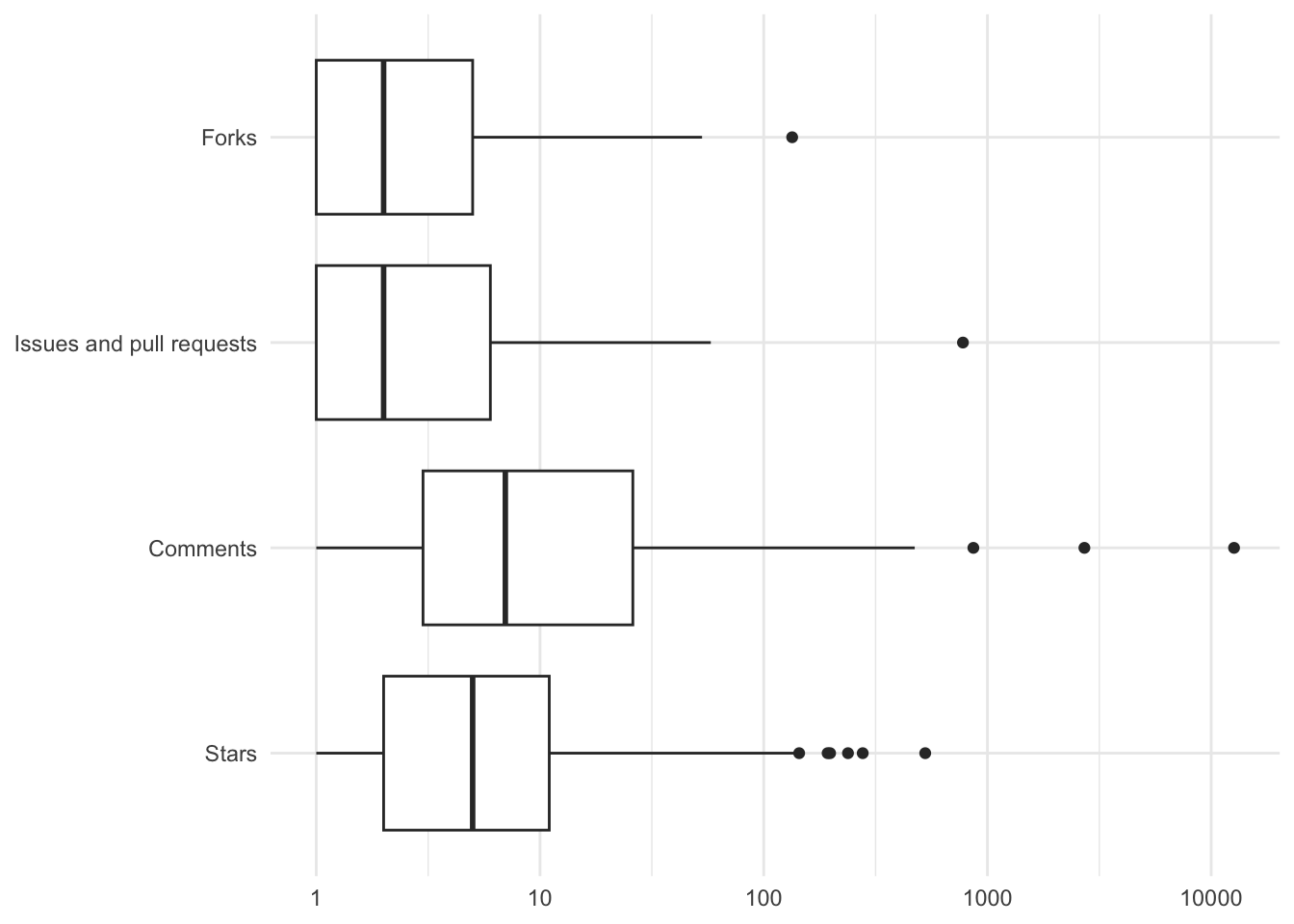
GitHub also facilitates collaboration on broader project management tasks, primarily through its issues feature.10 Unless a repository's maintainer specifically configures it otherwise, any user can create an issue attached to another user's repository, or comment on an existing issue. Issues are typically used to log and track bug reports, feature requests, and other comments and suggestions from the project's user base. GitHub's pull request feature is also implemented via this system - a pull request is a special type of issue. According to the data we collected from the GitHub API, these features are not widely used by open-archaeo projects (Figure 4). Only 46% of repositories have been forked at least once and only 38% of repositories make use of issues/pull requests. Those repositories that do use issues do not use them very extensively; 33% have only one issue and 85% have ten or less.
Another way GitHub users can engage with repositories and other users is with social media-like features such as starring a repository, commenting on an existing issue, or following a user. These actions populate a timeline of through which users can see recent activity and discover new projects related to those they have interacted with in the past.11 While not as direct a contribution as pull requests or issues, these features can facilitate the formation and maintenance of collaborative networks, in the same way that other social media platforms serve other professional networks. These features are used more widely than forks, issues and pull requests (Figure 4): 83% of repositories have at least one star and, in those repositories that use issues, 33% of them received at least one additional comment.
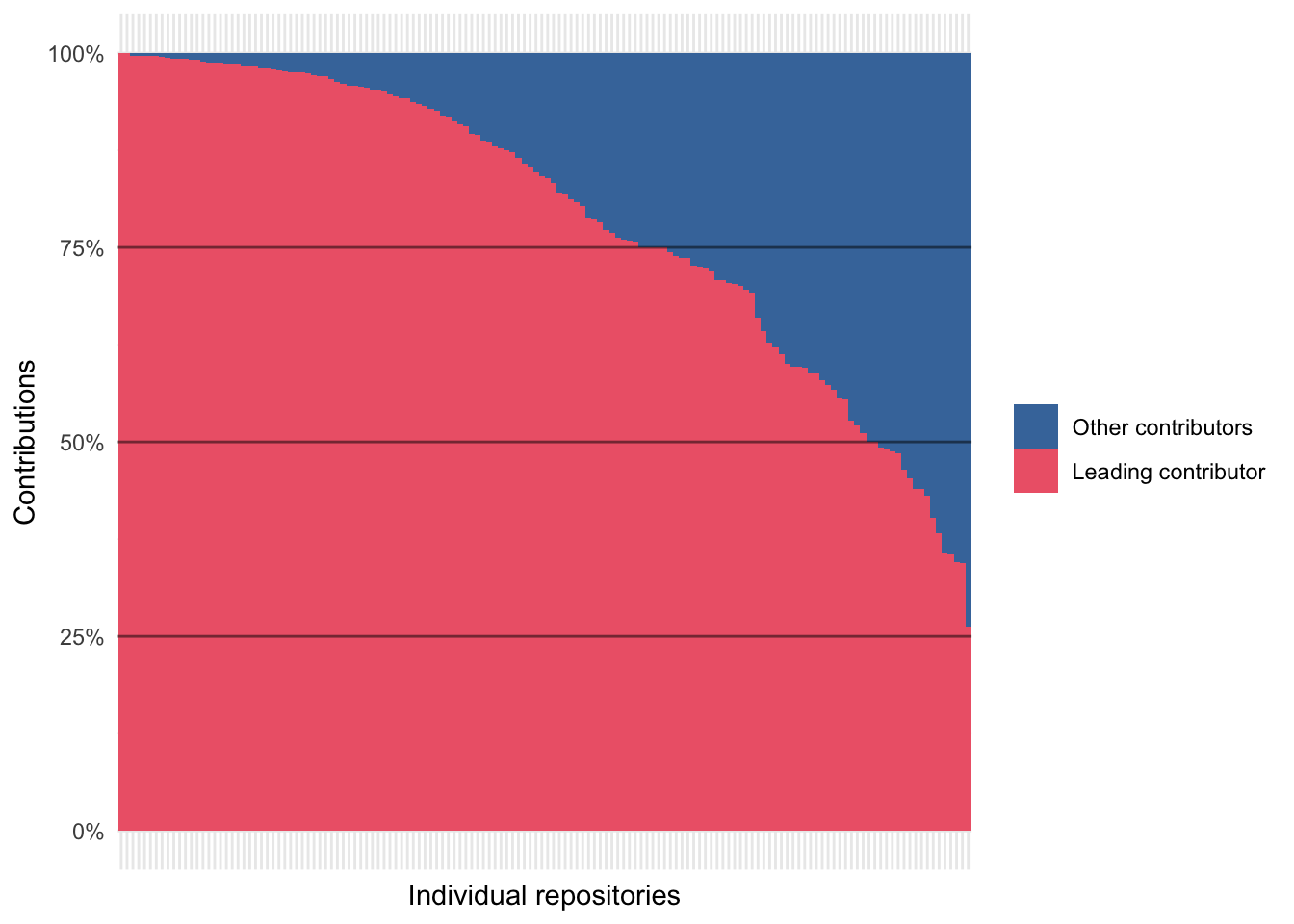
Perhaps unsurprisingly, given the low uptake of GitHub's collaborative features, 62% of open-archaeo repositories only contain commits from a single user. Even in the minority of projects that have more than one contributor, work (as measured by number of recorded commits) is distributed highly unevenly (Figure 5). The lead maintainer almost always does the lion's share of the work: they are responsible for more than half of commits in 88% of projects and more than three-quarters in 61%. This may be attributed to the steep learning curve commonly attributed to working with git. While git can be a great way to track changes and manage distributed contributions to a common code base, it can also be unwieldy in situations when multiple users (especially those with less experience using git for collaborative purposes) are expected to contribute within short spans of time. This corresponds with our prior observations that projects exhibiting higher commit rates have fewer contributors. Additionally, our analyses neglect to account for contributions that are not tracked via git or GitHub. Those who do not code may provide creative guidance or feedback during in-person meetings, via email, or using alternative online messaging or social media platforms. A more focused qualitative assessment of these non-coding and supportive work practices would shed more light on the totality of effort that goes into producing and maintaining open-source projects.
The prototypical open-source project comprises a core group of developers (often a single maintainer) that regularly commit new code, a wider network of collaborators that contribute through forks and pull requests, plus an active user base that create and comment on issues, who have indicated their support for the project by starring its repository. It is unclear whether archaeological software developers actually aim to operate following this model, or whether it is even suitable for supporting what open science aims to achieve. However, it is clear that only a small number of open-archaeo projects operate according to this model. The majority of projects are in fact short-lived, with few contributors and a small number of commits. Use of GitHub's collaboration features is also generally low (Figure 4), although the data also show a divergence between the uptake of features that facilitate direct code contributions (forks, issues, pull requests), which have markedly zero-skewed distributions, versus more indirect, social media-like features (comments, stars), which are moderately well-used.
These findings show a preference for passive/reactive rather than active/proactive engagement with others' work, which is not conducive to achieving the desired outcomes of opening source code, namely enabling greater engagement, reuse and critique. While limited time or technical capability may be contributing factors (which should be targeted in more focused investigations), we believe that social norms, such as expectations and taboos surrounding the permeability of a grant-funded project's boundaries, or whether it is proper to actively engage or interfere with work directed under the aegis of another project, play a very significant role. Our network analysis of collaborative ties, presented in the following section, corroborates this claim.
By contributing to shared repositories - whether with code (commits), issues, or comments - archaeologists using GitHub form a collaborative network that we can map using data from the GitHub API. Here we consider two facets of this network: repositories connected by common contributors (the repository-repository graph, Figure 7), and users connected by contributions to common repositories (the user-user graph, Figure 8). In both cases, number of contributions constitutes a natural measure of the strength or weight of the connection, which can be further broken down by type of contribution (commit, issue/pull request, or comment). We identified clusters using the edge-betweenness community detection method, which operates by locating the edges that are situated along the shortest paths between all pairs of nodes, and which therefore exhibit high betweenness centrality; these edges form indirect links between otherwise completely unconnected sections of the network, and as such are the loci that distinguish groups of nodes that are more highly connected to each other than they are to others (Girvan and Newman 2002).
 Home
Home