Cite this as: Evans, T., Hollander, H., Jakobsson, U. Gilissen, V. and Wright, H. 2024 Understanding current practice through case studies from established repositories, Internet Archaeology 67. https://doi.org/10.11141/ia.67.3
At the time of writing, the importance of digital preservation for archaeological and heritage-based data is more prominent than at any other point in the history of our discipline (Novak et al. 2023; Richards et al. 2021). Recent collaborations and projects, most notably SEADDA, have helped highlight the success stories but also the many and imminent risks and threats that still exist (Jakobsson 2021). One of the recommendations of SEADDA is that in order to counter these risks, we should establish communities of practice so as to better share tools, approaches, policies, and workflows. This is not a simple task of course; those organisations with the responsibility of curating archaeology will vary in size, may be autonomous or part of a wider infrastructure or organisation, have different funding models (including limited funding), and have to deal with variations in localised practice and legislation. Accordingly, there can never be a one-size-fits-all approach to digital preservation in our sector that can be held up as the “correct” way of working. However, thanks to the endeavours of organisations such as the Digital Preservation Coalition (DPC), there is now a more unified sense of what good digital preservation comprises and guidance on the routes to best practice (DPC 2015). This best practice extends into the world of skills and knowledge, with a recent and renewed emphasis on review and refreshment to guard against any erosion of capacity and to ensure that skills, technology, and policy remain fit for changing purposes (Currie and Kilbride 2021).
However, the amount of digital preservation tools is ever increasing and the landscape of information vast and dispersed amongst websites, blogs, conference papers, and social media updates (Cushing et al. 2021 53-54). A reaction to this has been the emergence of registries, principally the Community Owned Digital Preservation Tool Registry (COPTR), which aims to curate information on tools and workflows so as to aid finding, understanding, and implementation (Mita 2015). One of the potential weaknesses of this approach is the lack of discussion and reflection on these mechanisms and protocols that may guide a user to understand why something was implemented and its relevance to their specific scenario and needs (Cushing et al. 2021 59). This is a challenge that should be met by the community of archaeological data curators and principally those with long-standing policies and workflows that have changed or evolved over time. Organisations such as the Archaeology Data Service (ADS) have large portfolios of documents that describe their policy and strategy, often to very specific detail, and over time have developed in-house applications or utilised an array of proprietary and open source tools to achieve these aims and objectives. However, for an outsider to understand the “why”, it is imperative that efforts are made to better define and articulate these case studies so that they can be assessed relevant to the needs of the user.
The following paper is thus an attempt to introduce and discuss examples of workflows from three digital preservation practitioners in our sector. These case studies comprise three workflows, two procedural and one technical:
The specific and detailed workflows for assessing information, deaccessioning data, and preserving Microsoft Access Databases have been deposited in the COPTR registry, and the case studies themselves are designed to provide an overview of key points, each followed by a short commentary.
The ADS was established in 1996 and currently holds over 5 million files in 348 unique formats. The ADS receives on average 700 data collections per year, the majority through an online deposition tool called ADS-easy. A separate online reporting system called OASIS is also the route for accessioning around 7,500 grey literature reports each year. Depositors are primarily commercial archaeological units, but also include higher education institutions and independent researchers.
DANS was established in 2005 (see Hollander 2021), and currently holds c.150,000 archaeological datasets, comprising over 2 million files. In 2022, DANS launched the domain-specific Data Station Archaeology. This Data Station receives around 2,500 manual deposits a year, with 800 automated deposits (via the provincial depot system), and on average 18,000 Portable Antiquities of the Netherlands (PAN) deposits of metal finds found by members of the general public. Depositors are commercial archaeological organisations, either directly or via the provincial depot, academics, and PAN.
A key workflow for any repository is the checks and processes carried out on data when initially deposited by the data producer (Lavoie 2014, 12). Often these checks are - by the very nature of repositories - a technical exercise focussed on criteria including virus scans, corruption of data, and file authenticity and integrity. Another facet is more human-orientated and focussed on the usability (quality) of the (meta)data, and thus one that requires expertise and judgement of the repository staff involved. Repositories may take different approaches to how and when these assessments are made, as well as the course of resolution when issues arise.
The following case studies present each repository's method and approach to accepting and assessing data within their jurisdiction.
SND currently uses an in-house built management and documentation system called DORIS (DataORganization and Information System) for accepting and assessing data. DORIS is the only way to deposit data to SND. It can be used by universities using local storage that still desire to use SND's catalogue to describe and disseminate the project data. It is possible to make metadata searchable and accessible via SND's web catalogue without submitting data to SND. It is possible to describe data via DORIS that has already been published elsewhere if the data has a PID at that place.
The system is accessible by researchers and support staff from almost all universities in Sweden, researchers from other countries if they register an account, and SND staff. From SND's perspective, the researcher is the person who deposits the data and can be any project member appointed to perform this role. This is normally the support staff at most universities organised into what SND calls Data Access Units (DAU), however not all universities have such a unit at the time of writing. SND's role is classified as Research Data Advisor. When using DORIS, (meta)data can be published in SND's research data catalogue.
The workflow for the use of DORIS is described in two documents (both in Swedish): Kravbeskrivningen [PDF] (“requirements description”) and SND's policy för granskning av data och metadata [PDF] (SND's policy for reviewing data and metadata), and in the DAU-handboken (wiki in Swedish for DAU staff)). When a researcher wants to describe data in DORIS, they can choose between several profiles (Earth and Related Environmental Sciences, Engineering and Technology, General, History and Archaeology, Language Resources, Medical and Health Sciences, Natural Sciences, and Social Sciences) that consist of several optional or mandatory metadata fields.
Depending on what type of data and possible legal limitations, the researcher either deposits a copy of the data to SND CARE (SND's CoreTrustSeal-certified repository) or to their own university's storage solution, and then describes their data in DORIS. If data is deposited to SND CARE, it is SND staff that assesses the (meta)data. If the researcher is affiliated with a university that has a DAU, the DAU participates in the assessment. If data is deposited to the university's own storage, it is the DAU that assesses the information and checks the data to make sure that there is enough metadata and that the data file is readable, usable, and understandable. Only one entity (researcher/DAU/SND) can make changes to the metadata at a time and according to the Status of the record (see Figure 1). Communication between the researcher and the DAU, the researcher and SND, or the DAU and SND is documented in DORIS. When an entity considers itself finished with the editing, it passes on the editing right to the next entity or returns the right to a previous one for completion (see Figure 1).
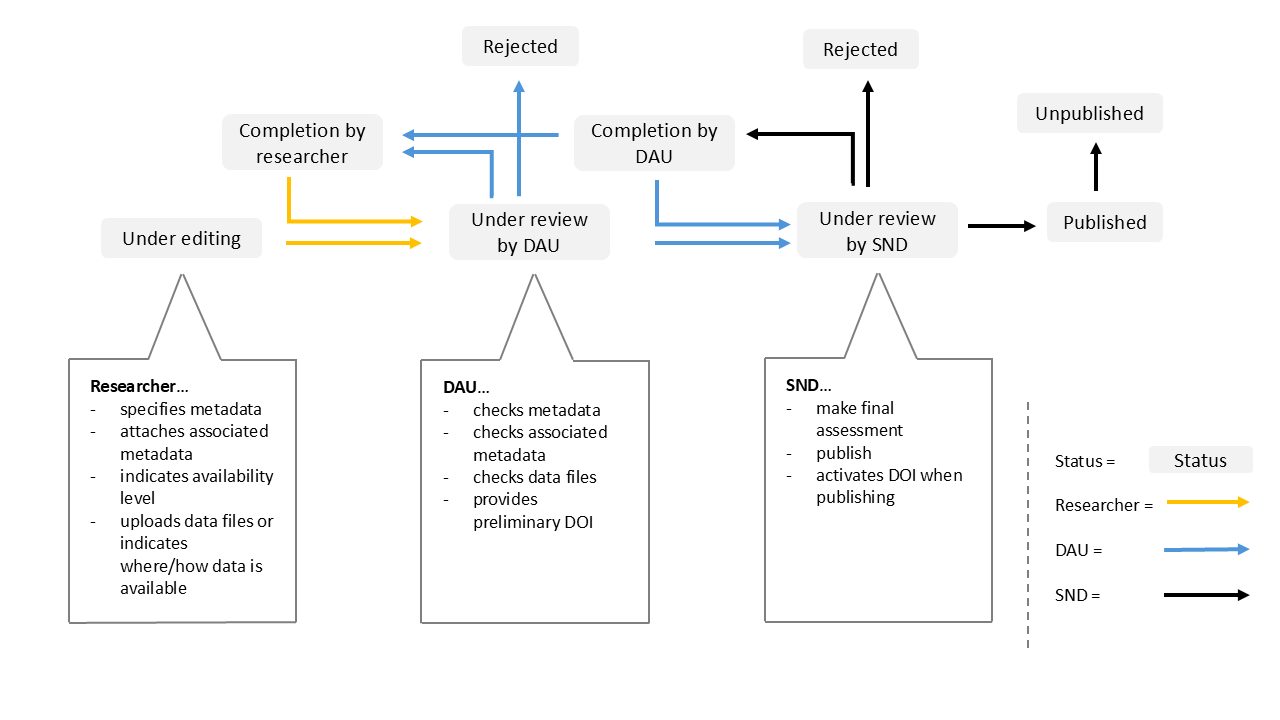
Data descriptions of data stored at SND CARE can only be published by SND. When SND assesses that the data description and any file(s) can be published, the status is changed to Published. If the data is stored locally, it is the local DAU that publishes the data description and the data. Each published dataset is assigned a digital object identifier (DOI) upon publication. However, a preliminary DOI is set at an early stage, but is only visible to SND staff. This can be shared with the researcher when needed if a journal requires a DOI before publication of an article. The preliminary DOI is not valid before the data description is published.
When assessing the data description (metadata in the web form based on different profiles), documentation, and data file(s) for data deposited to SND CARE, SND starts with the assumption that the data, attached documentation, and metadata are sufficient to allow a potential secondary user to find the data, assess its reusability , and re-use the data without needing to contact the researcher(s). The data must “stand by itself”. This means that SND staff check the data description, read all attached documentation to make sure that there is enough information, and open the data file(s) to check variable labels, possible abbreviations, etc. to make sure that it is understandable. Most importantly, SND staff check for any information that can relate to a living person since this affects where the data can be stored and whether or not it can be openly downloadable. As of today, SND have a list of preferred formats to use when depositing data. If data is in a common proprietary format, SND staff normally also convert the data to an archival friendly format.
A data description that is published can be updated by the researcher or DAU independently from SND and a new version is created. The changes that a researcher makes is assessed by the DAU, but must follow SND policies and the Kravbeskrivningen [see https://doi.org/10.34894/ZFRPU1 and PDF] ('requirements description'). If for any reason a new version of the data needs to be published, it is either the DAU or SND (depending on where the data is stored) that assesses the new meta(data) and publishes a new version of the data which also receives a new DOI. Information on the different versions can be read in SND's catalogue.
Data can be deposited with the ADS via several methods:
Regardless of the manner of deposition, all data deposited with the ADS are the subject of detailed evaluation in terms of scope, completeness, and quality. At the ADS, this is undertaken prior to formal accession (i.e. the act of accepting data). This is a distinct stage of ingest known as assessment and appraisal.
The assessment and appraisal event is undertaken by a member of the ADS Digital Archives team. The member of staff runs through a checklist to ensure that:
Usually these checks are made for all files submitted. However, for collections comprising over 1,000 images and/or text documents, the Digital Archivist only checks a representative sample of 10% of the file type.
In instances where issues are identified such as data is submitted in formats outside of the list of accepted formats or lack of metadata, the ADS will contact the Depositor with a full list of issues and required actions and ask that data is re-submitted or otherwise resolved. If the Depositor is unwilling or unable to address said issues within a set time limit, then that part of the deposit may be refused or the deposit refused entirely. Any issues and resolutions identified during assessment and appraisal are stored as documentation (usually TXT files) within the archive information package (AIP). In certain cases, the Digital Archivist may make these fixes themselves. This is a judgement call and is only made in clear-cut cases of human error and as long as it did not impact the significant properties of the object in question.
Confirmation that the repository has accepted the dataset is made via the issue of a formal deposit receipt listing the data accepted and any notes or comments. This receipt is stored within the AIP as administrative metadata. Only once the deposit receipt has been issued and the data formally accessioned has the transfer of responsibility from Depositor to repository been confirmed.
After the point of formal accession, the ADS policy is generally not to allow Depositors and Curators to make amendments to datasets. There are exceptions in this workflow however (see Repository Operations for more detail).If a Digital Archivist spots an issue with the data after appraisal and accession, but before completion and public release of the dataset, then two options are available:
If a Curator or Depositor spots an issue with the data after completion and public release that requires replacement of an object with a revised to significantly corrected version, then this usually requires a new version of the archive.
There are exceptions to this rule, which, as with unreleased data, are usually simple corrective procedures or redaction of information under sensitivity concerns or UK General Data Protection Regulation (GDPR). In these cases, the DIP and AIP versions of the object are amended as an 'Editing - Corrective' event. This is performed on the AIP and DIP versions and logged as a formal process allowing another Curator to understand the provenance. It is a core policy that after accession, the SIP cannot be modified by the Curator or Depositor, only deaccessioned according to the procedure described above.
Datasets can be deposited at DANS via the following routes:
DANS allows Depositors and Curators to both make amendments to datasets (including data and metadata), as described below, and will record the identity of the person making the change in its provenance records. Changes can only be made to dissemination copies of the dataset (including data and metadata). These are managed in accordance with 'Data Management' provisions and will result in new versions of the dataset.
The SIP cannot be modified by the Depositor, and can only be modified in exceptional circumstances by the Curator. The AIP can be amended from time to time by the Curators pursuant to bit-level and format preservation, and cannot be altered by the Depositor.
With the exception of machine-to-machine deposits (see above), every dataset submitted to DANS will undergo basic curation according to the Data Stations Policy and an internal Data Processing Team manual. Basic curation includes the following verifications:
In the case of large datasets, it may not be possible to check the readability and validity of every single file. A representative selection of files may be checked instead, with the Data Manager using their own insight to assess what sample is satisfactory. Larger datasets are often large because they come with many images which can all be scanned in a thumbnail display.
In each case study, the repository takes a leading role in ensuring that data meets a minimum standard, with a shared emphasis on ensuring that metadata is present and that it adequately describes all the data objects deposited. A possible divergence is on sensitive data, with DANS and the ADS including appraisal within their checks. Another notable difference is that for large collections, the ADS adopts a 10% sampling strategy for some aspects, such as the aforementioned scan for sensitive data issues. Whilst reducing the time taken for assessment, this increases the risk that problematic data moves through ingest, and thereafter may only be detected during the creation of the AIP and DIP and after publication.
Aside from what is being assessed, the differences mainly relate to how this assessment is made and the paths to issue resolution. For DANS and SND, the online management system/portal for deposition is used as both the means of delivery and assessment. In the case of SND, the use of DORIS to facilitate and record a conversation with themselves as the repository, the data producers and the DAU. While the ADS follows a similar workflow of checks (often performed locally) and issue resolution to SND, this is currently undertaken outside of any one system and the decisions and issues that go into the final SIP are documented within the AIP itself as administrative metadata. The decision (and ability) to capture such conversations within or outside a management system is perhaps moot as the process itself is documented in either case. It is however for repositories to consider how these decisions, which go a long way towards dictating what is in the SIP, are documented, archived, and ultimately reflected within the final AIP/DIP accessed by data consumers. In simple terms, repositories should help an end user understand how a dataset came to be in a format and what was potentially omitted or changed.
It is also interesting to note the different approaches to issue resolution between the case studies. The ADS approach places the onus on the data producer to meet repository requirements, with Digital Archivists only making corrections or amendments on rare occasions. Through the hierarchy implemented in DORIS, these requirements and issue resolution are perhaps better overseen through the assistance of the DAUs resulting in a more iterative process. In slight contrast to the ADS, DANS staff do take a more proactive approach to dealing with smaller issues within datasets, such as the editing of metadata and directory structures.
A universal consideration for all repositories is the removal of data. A repository may be asked to remove, or themselves identify the need to remove, data for a myriad of reasons including but not restricted to:
It is essential that a repository has a procedure in place to deal with cases where users can identify issues or otherwise request that data is removed. The repository must ensure that procedures are in place to ensure a clear responsibility for decision making, that staff understand the protocol for removing data, and that this event is documented.
In the current age of open access data publication and citation, the removal of data that may have formed the basis of research or decision making is not something to be approached lightly. Links to removed objects or collections should still resolve to an appropriate page, ideally with the provenance recorded (i.e., that the material has been removed and at what time). These workflows and procedures form an integral part of being a 'trusted repository' and ensure that any privacy or confidentiality concerns can be reasonably addressed, but within a framework where such events are adequately documented and understood by users.
De-publication of data can be made on request by the researcher, the DAU, or by SND. The reasons for de-publication should always be documented in DORIS. SND follows DataCite's recommendations regarding de-publication and a so-called tombstone page for data is saved. It is always SND that manually removes the data. If data is stored at SND then they make the decision, otherwise the university is responsible. (See an example of a deaccessioned dataset from SND).
The ADS makes a distinction between disposal of non-accessioned data, for example a deposit that stalled or was otherwise cancelled, and the formal removal of data that has been accessioned. In most cases, accessioned data has been issued a DOI and potentially cited, but variations do occur. The following scenarios are detailed in the workflows deposited in COPTR:
In all cases, a request to remove files from an ADS archive will be made in writing to the ADS, clearly stating the reason for said removal. The Collections Development Manager will issue a holding response acknowledging receipt of the request. This response will also outline that repository staff will conduct an appraisal of the record and the associated dataset and that a response will be forthcoming. A Digital Archivist will conduct an appraisal of the request and report the likely impact to the Collections Development Manager. Where the Depositor(s) agree with the repository's findings, an agreement will be sought, and a plan arranged on the best approach to address the issue.
In some instances, the Collections Development Manager may decide that consultation with identifiable stakeholders who have a legal or ethical interest in the dataset is required. This may include:
These discussions will commence prior to any data removal or formal deaccession.
It is ADS policy to ensure that anyone that has citations to resources that have subsequently been removed are retained, and furthermore, that the provenance of the deaccession or removal is recorded within all associated metadata.
Persistent identifiers (i.e., DOIs) for any removed content will remain in place, and will in no case be removed. The DOIs will resolve to a landing page of the original metadata, with a further description making it clear that the dataset has been withdrawn. The ADS will update all required internal metadata to indicate that the resource has been removed. This will be replicated in DataCite metadata and any external aggregators or metadata services.
Datasets deposited in the Data Station are potentially cited either in the original research or in derived research. In both cases, the datasets should remain available for validation (reproducibility) considerations. This means that datasets are only deaccessioned (removed from publication and open availability) or deleted in special circumstances.
Datasets can be deaccessioned when:
Datasets and deposits can be deleted:
In all cases where access to a published dataset is terminated, a notice will be added to the landing page of the PID associated with the dataset to indicate that the dataset is no longer available.
If there are sufficient grounds to decide to deaccession a dataset, the deaccessioning is done by a Data Manager. Dataverse enables the Data Manager to select one or more versions of a dataset to deaccession. A reason needs to be stated for the deaccessioning, which can be selected from a drop-down list of valid reasons (e.g., 'Legal issue or Data Usage Agreement') or otherwise described.
The DOI will always lead to the most recent available version of a dataset. If one or more versions of the dataset are deaccessioned, it will be clear that there are deaccessioned versions on the versions tab of the dataset, along with the reason given for deaccessioning. The user will not be able to view or access the deaccessioned version at all. If all versions of a dataset are deaccessioned, the DOI will lead to a tombstone page informing them that the dataset was deaccessioned, with the reason given.
Although each repository has a similar policy, primarily the ability to react to notification of an infringement of copyright or GDPR, there are some interesting differences. The DANS policy clearly states that removal may occur where “content is unlawful or the dataset is fraudulent from a scientific point of view”. In the case of the ADS, the reasons for removing data are not explicitly stated, only that any issue (presumably including a complaint against a fraudulent dataset) is made to the Collections Development Manager. The ADS workflow is also highly varied. Differing scenarios on whether an object or collection has to be removed create differences in how this process is handled within the team and thereafter documented. This is also complicated by the theoretical requirement to other parties that may have required preservation of a dataset as a condition of funding or other legal consideration. This potentially adds a significant time overhead to the ADS as various steps and procedures are worked through. This has the advantage of ensuring that removal of data is documented and transparent, but represents a hidden cost that is often borne by the repository themselves.
The core similarity is that each organisation maintains the PID for the removed dataset.
A database is a collection of data items and links between them, structured in a way that allows it to be accessed by a number of different applications programs. The most common forms of databases used in archaeology are flat file and relational databases, although there is a growing movement towards the use of object-oriented database models. The ADS Guides to Good Practice state:
In flat file databases there can be an inherent looseness in the way that data is defined and recorded along with a significant duplication of sets of information from record to record. The relational model addresses these and other issues by requiring a data structure to be pre-defined and by splitting related groups of attributes into separate tables which are then linked together through key fields (Primary or Foreign keys). In contrast to spreadsheets and many flat file databases, most database applications allow (and in fact require) the strict specification – in terms of field length, data type (numeric, etc.) of the data types to be recorded. Databases can potentially consist of more than just data values. Forms, used for data entry or for running queries, are often the only way in which many users interact with databases and can be viewed as part of the database but separate from the data itself. Likewise, the queries and results or reports that result from user interaction may also be considered as 'non-data' components of a database” (Archaeology Data Service 2023).
The preferred format requirements of all the repositories in this case study, particularly the ADS, often place the onus on the data producer to supply the data within a database in a non-proprietary format such as series of delimited text files. That being said, depositing in proprietary formats is still common. A recent study by DANS of deposits between 2000 and 2020 has shown that Microsoft Access databases are still deposited in relatively large numbers, with nearly 300 deposited as MDB files in 2020 (DANS 2022). Of interest is the presence (but relatively lower numbers) of databases deposited in the newer ACCDB format. The low use of this newer files format is attributed to cultural attachment to models of templates created in earlier formats as well as a more general trend to use spreadsheets (DANS 2022). The same trend is present at the ADS, with 1,190 Access databases (1137 MDB and 53 ACCDB) deposited since 1996. In contrast, SND holds 350 databases exported from the Intrasis system. The reliance of data producers on a proprietary format such as Access, particularly the older version of MDB, poses a significant risk when considering the recommendations for database preservation (DPC 2021 3).
Microsoft Access databases deposited to SND and stored in SND CARE are stored in their original form. The data is shared as MDB files, however the data is also stored and shared as separate CSV files and XML files. Data is exported from the Access database via a self-developed Python script. The script was made in Python 2.7 and converts, checks the format, renames files, defines projections in the GIS files, and creates and names new folders. Together with the csv files, a schema.ini file is provided with information regarding the column's name and size (remnant from the mdb export to csv). When the format is upgraded, a new version with information is published. Access databases stored locally at a university are managed by that university in accordance with local archival policies.
In deposits, the ADS accepts the following versions of Microsoft Access:
In the assessment phase, the Digital Archivist will check that the following metadata is present for any Access database deposited:
The Digital Archivist will:
Following assessment, data can then be accessioned and the original Access database is stored within the SIP.
The next stage is the creation of the AIP and DIP, which comprises normalisation to CSV format. The ADS use two main workflows:
After creation of the CSV files, the Digital Archivist will:
Where possible, CSV files should retain the same name as the original database with the table name appended. However, it may be necessary to change the table names. Where possible, CSV files should retain the same name as the original database with the table name appended. However, it may be necessary to change the table names in the case of obvious spelling errors or cases where the table name is vague or cryptic. For example 'desrciptions' (sic), 'table1', or 'mypottb'.Any changes to database or table names within the preservation or dissemination versions should be recorded in the process metadata as 'Editing - Corrective' events.
In all cases, the CSV versions will also form the basis of the DIP, made available through the ADS website. In specific cases, the original Access database will also be made available alongside the CSV versions. The file is made available under a separate statement warning the user that this is a proprietary format, which raises issues over long-term support. Cases such as these are rare, and usually occur when the Depositor has flagged items such as the forms or SQL as being useful to the target audience. The ADS will host these upon request, but recommend that SQL statements or other forms of 'content' are best included within a piece of supporting documentation supplied with the database that helps users with specific queries.
The preservation package (AIP in OAIS-RM terms) may differ from the SIP with regards to format as files may have been converted by DANS to guarantee long-term readability by humans and machines. DANS maintains a list of preferred file formats and will ensure that these reflect the needs of the designated community and the requirements of current technology. When DANS performs file format conversions, a new version is created and the original submission will be retained.
DANS guarantees the long-term sustainability of data in formats which DANS lists as preferred formats. Whenever DANS makes changes to the guidelines to the effect that a preferred format becomes a non-preferred format, DANS is responsible for the migration of all archival files in non-preferred formats to preferred formats. DANS accepts non-preferred formats, but cannot guarantee their long-term sustainability nor is it responsible for keeping these formats sustainable. DANS will ensure that the preservation packages retain integrity through measures aimed at preventing bit-level information loss. DANS will evaluate formats from time to time and make adjustments to preservation packages to guarantee continued readability by humans and machines. When outdated formats are migrated to successor formats, the archival metadata is updated accordingly. Files in outdated formats are preserved to maintain the chain of provenance.
In practice, the non-preferred file formats for databases (MDB, ACCDB) created by Microsoft Access are widely used. However, the MDB and ACCDB formats are very poorly supported outside of Microsoft Access, which is proprietary. Due to the different versions of these formats, it is possible that different versions of Microsoft Access itself do not always support the files properly.
For the time being, for many databases created with Microsoft Access, DANS has provided sustainable and accessible formats by storing the tables from the databases as separate CSV text files. Tables can be exported from Access via an Access-form. This is a form within an Access database which is available via the DANS website. The download includes a readme file with information about the use of this tool. The form can be used to export all tables within the database to standardised, preferred CSV files. The form can be copied and pasted into another Access database to use for exporting tables from that database. It is also possible to import an external data table or spreadsheet (such as an Excel spreadsheet or a DBF file) into this database, then export that table to CSV.
Storage of the tables as CSV files only retains the tabular data from a database. Any overarching documentation needs to be described in a separate document accompanying the CSV files. Within Microsoft Access, the “Database documentation” function can be used to generate a document with column descriptions and table relationships. This document can be saved as PDF/A as formatted text and supplied with the tables of the database. In addition, care must be taken that all codes and variables used are explained, which can also be done by providing further descriptions in a separate document (“codebook”).
It is notable that out of all possible formats and flavours of text, each repository uses CSV as a format for preservation and dissemination. At the ADS, the decision to use CSV (instead of Tab Separated Values (TSV) or even TXT files with Tab or Pipe delimiters) is driven by user familiarity (both internal and external), that most standard software applications such as Microsoft Excel can open CSV with minimal human intervention, and the fact that CSVs do not require additional metadata to document the delimiter. That being said, it is interesting to note that SND and DANS also provide the original Access database and SND additionally provides an XML as an alternative machine-readable format. This potentially offers a greater variety of re-use scenarios, subject to the support for MDB/ACCDB being in place. This highlights a dichotomy within the AIP: on one hand, the concept of a disposable/shorter-term format that can still provide a role in facilitating access and re-use, and on the other, the resolution to break the entity down to its component parts that require an end-user to rebuild. As noted in the introduction, both solutions are equally valid in presenting data to users, but it is arguable that a user of SND may have less steps to rebuilding a database than a user of the ADS. Conversely, the potential overheads for providing access to a single format is lower than providing multiple. It would be interesting to measure this 'cost' against the benefit of reuse - for example, are databases more likely to be downloaded if available in a variety of formats?
The three case studies in this paper demonstrate that while some technical and methodological aspects of digital preservation in archaeology may vary, our problems and goals are reassuringly the same. Indeed, the differences in methods and approaches documented herein are related more to the in-house technical platforms and solutions implemented over the historical development of the organisations than to any conceptual divergence, with the three repositories unified by a singleness of purpose (c.f. Ahmad et al. 2023). While some variance is due to the context of the organisation and the role which they play within a national framework for digital data in their regions, many of the decisions share a common theme of fulfilling and balancing the needs of both the designated community, the archive itself, and end users. The continued sustainability of all three approaches is in contrast to any hypothetical concern over diversity in the implementation of digital preservation solutions.
A key theme within each case study is the importance of the ability of each repository to adapt tools and solutions that fit their needs. It is notable that none of the case studies uses a third party digital preservation system, but have instead developed solutions in house. This is particularly important when looking at the aspect of actually “doing” active digital preservation as exemplified by the case studies on dealing with Access databases. Each organisation has developed a home-grown solution for normalising files into CSV, with the primary objective to get data out by whatever means works. As demonstrated, there is no need for overly developed workflows or technical solutions when a relatively low-tech solution fulfils the objective. For a nascent or developing digital archive, it should, we hope, be reassuring that digital preservation does not need to be time consuming to implement or always require a third party system (Rieger et al. 2022).
Conversely, it is significant that all repositories have invested time and resources in developing an ingest and accession mechanism for datasets. Each system has been designed to both simplify the act of depositing an archive - with all the considerations of file formats and metadata that entails - but also to facilitate and expedite the archival process. As the ADS - at the time of writing - still accepts data by other mechanisms including physical media, it would be interesting to examine in more detail the cost/benefit of an online deposit mechanism versus other means so as to identify what core services are essential for a digital archive. For example, if a certain level of data (in terms of deposits but also size of data) is expected, is an online deposition tool therefore essential for success? If so, this would have ramifications for any new service that may be assessing requirements for their digital preservation system. That being said, there are still different viable scales and methods of ingest application: DORIS and the Data Station arguably represent more developed and streamlined workflows of curation, whereas ADS-easy presents a mechanism for transfer with the in-depth review coming after the event rather than in the system itself.
Streamlined or not, each case study requires human resources to appraise and assess data, task that can require a certain level of familiarity and knowledge of the format, but also of the content itself. It could be argued that for smaller organisations with less staff resources, this approach may not be sustainable. However, as demonstrated by the case studies, we would suggest that simply having a policy that reflects what you are able to do is more important than a policy which aspires to the unreachable. To quote an old adage, one should cut one's coat according to one's cloth. Less does not necessarily mean a lesser archive. On this note, it should not be overlooked that policies and workflows themselves are cultural products and relics of people's concerns and priorities, which themselves may be based on their work with the designated communities in their regions. We should remind ourselves that this is fine, but also that reflecting and sharing can be good for re-evaluating our own ways of working.
Internet Archaeology is an open access journal based in the Department of Archaeology, University of York. Except where otherwise noted, content from this work may be used under the terms of the Creative Commons Attribution 3.0 (CC BY) Unported licence, which permits unrestricted use, distribution, and reproduction in any medium, provided that attribution to the author(s), the title of the work, the Internet Archaeology journal and the relevant URL/DOI are given.
Terms and Conditions | Legal Statements | Privacy Policy | Cookies Policy | Citing Internet Archaeology
Internet Archaeology content is preserved for the long term with the Archaeology Data Service (ROR). Help sustain and support open access publication by donating to our Open Access Archaeology Fund.
 Home
Home