The Reference Database is a core component of the ArchAIDE system and provides data to all the other components. The design and analysis phase involved input from all the archaeological specialist partners to gather the necessary design requirements. The development of the software tools were implemented using 'Agile' software development methodologies, in order to continuously deliver versions of the final system to the partners for testing. Each design-develop-test-refine cycle (about 2 weeks) included a partial revision of the requirements and functionalities of the system. The tight cooperation with the partners allowed the creation of both useful and robust tools. The Reference Database contains the definitions of the pottery types, the decorations, stamps, fabrics, and other information needed by archaeologists during sherd analysis.
The Reference Database includes data created and managed by different users, from a variety of sources, concerning different ceramic classes and historical periods; thus the data are organised in catalogues or archives created and managed by and for specific groups of users (Figure 3). The main entities within the Reference Database are:
The information associated with a pottery type includes:
The content of the media may be verified by specifying its media form such as: Whole vessel, Rim sherd, Base sherd, etc. The field 'External id' is the handle connecting the reference database to the machine-learning models for automatic classification. The deep-learning model, resulting from a classification request, returns a list of codes corresponding to types (shape recognition) or decorations (image recognition); the codes used are the same as those present in the type definition as an external id.
The ArchAIDE Reference Database application was developed in Java using the Grails Application Framework and runs on the following stack (from top to bottom):
The data are stored in a relational database (MySQL) and indexed for advanced search and API support (Elasticsearch). All the multimedia files related to database entities, such as depictions and 3D models, are stored in the file system.
The reference database is integrated with the following:
In order to make the Reference Database able to exchange data with external systems, the ArchAIDE partners defined a data exchange format based on JSON, and to define an API interface allowing external data to be sent and received. The availability of a well-defined data format allowed the partners to export it mapped to the ArchAIDE schema using existing digital comparative data and see it imported in the Reference Database. This was the case for Roman Amphora and CERAMALEX. The format was also used in the process of extracting information from printed pottery catalogues.
The definition of an API interface is essential for the Reference Database, in order to provide information to the ArchAIDE App and to external systems that need to synchronise their data with ArchAIDE. To include geographical information in the database, it was decided to use GeoJSON as a format to represent geographical features (both points, lines and polygons). Location in GeoJSON is represented by a small amount of text in JSON format, thus it is easy to store in the database.
The mappings were supplied to Inera (as JSON and CSV) for incorporation within the reference database. The multilingual vocabularies have been implemented as the basis for establishing a clear level of semantic interoperability within the reference catalogues imported into the database.
The choice of the pottery classes, and consequently the catalogues to be used for the ArchAIDE project, was one of the main issues to be considered in order to create a system that must have a real-world implementation. The decision was made to choose three types: amphorae manufactured throughout the Roman world between the late 3rd century BCE and the early 7th century CE; Roman Terra Sigillata manufactured in Italy, Spain and Gaul; Majolica produced in Montelupo Fiorentino (Italy) from the 15th to 18th centuries, and medieval and post-medieval Majolica found in Barcelona. The choice of pottery types was based on the availability of collections to the ArchAIDE partners and their areas of specialist expertise, and the need to find types that relied on both shape-based and decoration-based characteristics for identification.
In addition to the Roman Amphorae and CERAMALEX digital collections, the database was also populated with analogue catalogues, which had to be digitised (see Section 2.2.2). These were in the form of catalogues, books and papers (Berti 1997; Bustamante-Alvarez 2016; Ettlinger and Römisch-Germanische Kommission 1990; Dragendorff 1895; Gascón et al. 2017; Fornaciari 2016; Gempeler 1992; Peacock 1972; Keay 1984; Simpson 1985; Medri 1992; Montes et al. 2010; Wilson 2002).
Databases are common tools for archaeological work, but for different reasons (e.g. technical, legal or historical research traditions) each project, excavation or research community develops their own database structures, naming conventions and data workflows. This leads to a very heterogeneous situation for data provision, even within the same field of research. This is reflected in the two digital sources imported into the database:
In order to enable data exchange between the ArchAIDE database and existing external sources like Roman Amphorae: a digital resource and CERAMALEX, the project partners decided to define a JSON-based data format, derived from the ArchAIDE database schema, to be used in both import and export transactions. The JSON format was intended to represent the content of a catalogue (i.e. 'Roman Amphorae') and contains definitions of pottery types, fabrics, decorations, stamps, places, etc.. The external sources should provide a JSON file or a compressed (zip) file containing the JSON file, plus all the multimedia resources associated with the described entities.
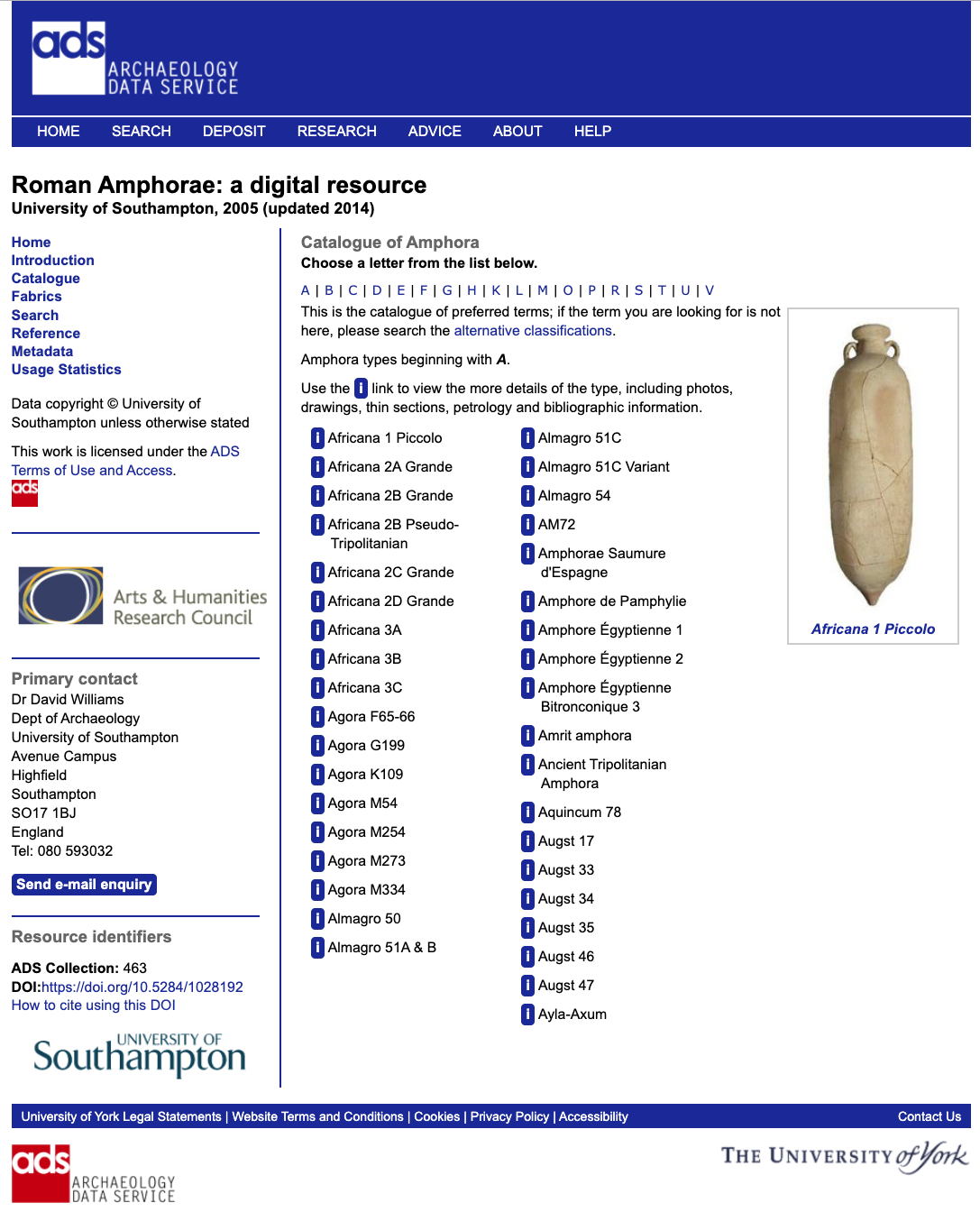
Using the import tool provided by INERA as part of the ArchAIDE Reference Database Management System it was possible to import both the ADS and CERAMALEX catalogues. In particular, the Roman amphora catalogue from ADS was the first external source integrated because of the similarity between the conceptual schema of the databases (Figure 4). The work on the CERAMALEX database was more complex because the database schema and architecture led to a different focus of pottery research. The differences between the two systems required complex mapping and normalisation activities, ending with the creation of an ArchAIDE catalogue imported from the CERAMALEX/CeramEgypt database, with the mapping and normalisation process leading to the revision of the ArchAIDE database. Therefore the already structured database with totally different data structure, CERAMALEX/CeramEgypt, was used as proof of concept for the import approach.
Paper catalogues contain all the geometric and semantic information needed to populate the reference database and train the image recognition algorithm. This information is presented as both textual description and diagnostic drawings. Digitising these catalogues transforms them into structured/annotated data that can be used within a database, and is also searchable and machine-readable.
The paper catalogues were scanned as images, and then textual information was extracted corresponding to the relevant fields within the database, along with the drawings of the pottery types (which were then processed to trace their profiles, as explained in Section 2.2.3). While the drawings were more standardised, in terms of uniformity and information content, the structure of the textual description varied greatly between catalogues. It was possible to find both highly structured catalogues, where each type is described individually with a series of fields (very similar to a database), and non-structured catalogues, where the various types are verbosely described as free text, without any recurring, definable structure. It was therefore necessary to create a tool able to deal with both structured and unstructured catalogues.
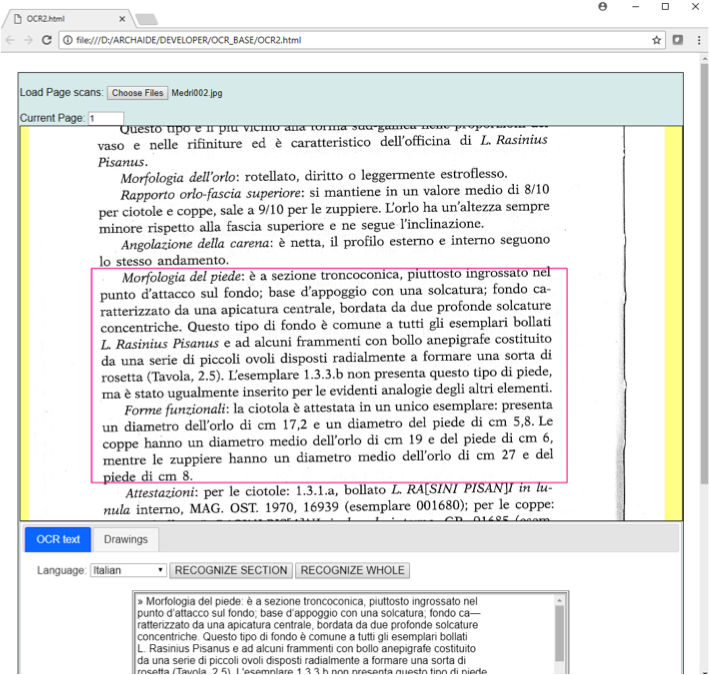
This division made it easier to create the interface for the digitisation tool (Figure 5). JavaScript worked well with the web database backend and the metadata structures, as HTML/JavaScript supports images and text manipulation, and rendering of components. Text recognition functions were implemented using the Tesseract OCR, a widely used open source OCR tool, available on multiple platforms, including JavaScript. The 'structured catalogue' digitisation tool worked by combining OCR with the structure used in the catalogue, to describe each type (e.g. the number and order of paragraphs, their position within the pages, recurring keywords and section titles, and/or the presence of bulleted and numbered lists). Starting from the output of the OCR, which contains all the columns/sections/lines/words in the page, the tool automatically splits the description into chunks following the catalogue structure template. The chunks are used to fill the database fields representing a pottery type.
Unfortunately, each catalogue may employ a different structure to describe the types: it then becomes necessary to adjust the parsing process to accommodate the new template. This task of creating a new 'structure parsing template' must still be carried out manually, as the number of structured catalogues was so small it was not useful to create a higher level description of these templates. The output of this processing tool was a series of JSON data structures (containing the different data fields extracted from the catalogue) and images (cropped from the scans), describing each type of pottery. These data were then directly imported into the database, generating the types and associated visual depictions. This was a one-time batch operation, due to the limited number of structured catalogues; thus the tool was used as a stand-alone process, not integrated into the database backend.
The 'unstructured catalogue' digitisation tool was integrated directly into the database backend, to be used by the archaeological partners when creating a new pottery type. In this instance, a fixed structure could not be used, but it was still possible to use OCR to digitise chunks of text from the catalogue scans, speeding up the data entry. The interface lets the archaeologist load multiple scans and browse them. The user reads the text, and when they find a part of the text that can be used to fill one of the database fields, they select it and the tool selectively applies OCR to the selected section. The text may then be edited, to correct errors, or add user-created content. When the text is ready, the user chooses to which database field this text should be assigned. Similarly, from the same interface, images may be marked, cropped from the original images, and inserted directly into the database as visual depictions associated with the new type.
Pottery profile drawings in catalogues use a standardised geometry, but the semantic information is flattened in a single raster layer, and encoded following specific representation rules. Designed for human interpretation, this representation is not machine readable. A vector-based representation allows the separation of different semantic and diagnostic elements. It was suitable for use in the Reference Database, but was also found to be useful for training the neural network. Using image processing techniques developed by CNR-ISTI for ArchAIDE, and exploiting the common representation rules of pottery profile drawing in archaeology, it was possible to vectorise and create semantic elements in an automated way (Figure 6).
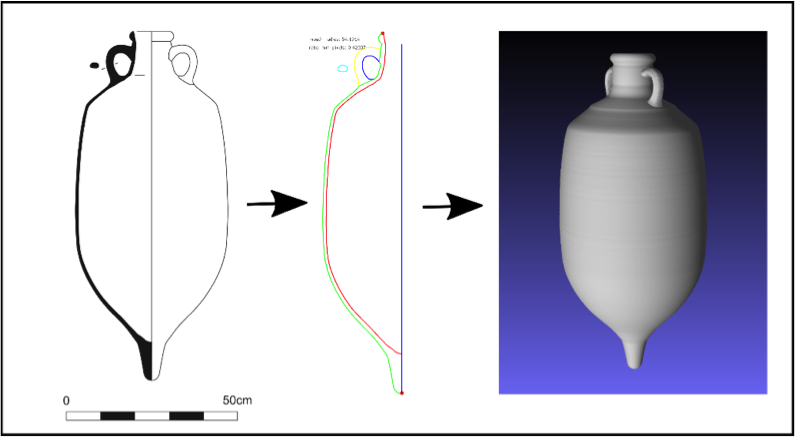
The aim of this process was the extraction of several geometric and semantic features (body/handles profiles, rim, base, rotation axis). The extracted profile was then stored as an SVG file, and annotated with semantic information. In this way, it was possible to create a digital visual representation (for human access), but the data were also machine-readable. Image-processing techniques also made it possible to generate a 3D model of the traced vessel. The profile extraction was automated, but was able to accommodate small inconsistencies in drawing style across different catalogues, and required only minimal adjustments. The tracing process was implemented as a Matlab function, which could be a batched execution, generating SVG tracings and 3D models for all the drawings in a single catalogue in a matter of minutes.
The tracing of profiles followed a series of steps. First, the scanned image of the archaeological pottery profile was cropped and binarised. Then, a dilate and erode operator was applied to remove any possible pixel outliers resulting from scan noise and printing imperfections. The rotation axis of the vessel was then found, using a Hough transform, isolating the longest vertical line in the drawing. From this axis, the 'profile' side of the drawing was isolated: typically, pottery drawing conventions dictate profiles are drawn on the left side, while the external surface is described in the right part of the drawing, while characteristics such as orientation and drawing style (filled, empty, hatching) may not be consistent between catalogues.
It was then necessary to extract the actual profile regions: external profile, internal profile and handles. The drawing was segmented to extract all the edges. Starting from the axis, the inner profile curve was found, then using a 'marching' process the whole inner profile was traced, going from the top point to the axis. The outer profile was slightly trickier, as it might contain a handle. If a handle was detected, its profile was isolated and trimmed from the outer vessel profile, using an energy function that provides a trimming surface that is smooth with respect to the rest of the outer vessel profile. The cut-through section of the handle, if present, was isolated and traced separately. In addition to the axis and inner/outer/handle profiles, other metric and semantic information (position of rim and base point, mouth radius) were automatically computed and stored in the SVG. The physical size of the profile could be extracted automatically if a scale bar is present in the image, or recovered starting from the DPI value of the image, and if the information was present in the catalogues (each catalogue/page might be drawn at a specific scale).
Once all the elements were traced and saved in the SVG, a further step produced a 3D model (Figure 7). This 3D model is a simple representation, aimed at visual presentation. The body of the vessel is a simple rotating object, generated from the profile. For vessels with handles, 3D models for the handles were generated as parametric extrusion along with the handle profiles. Then, the main body is trimmed, and the 3D models of the handles were welded in place. Managing the handles was not always straightforward, as the information in the drawing may be incomplete (e.g. only the profile of the handle is shown, with a middle cross-section, or sometimes not shown at all). These 3D models are available in the desktop Reference Database and can be interactively visualised in the pottery type database page.
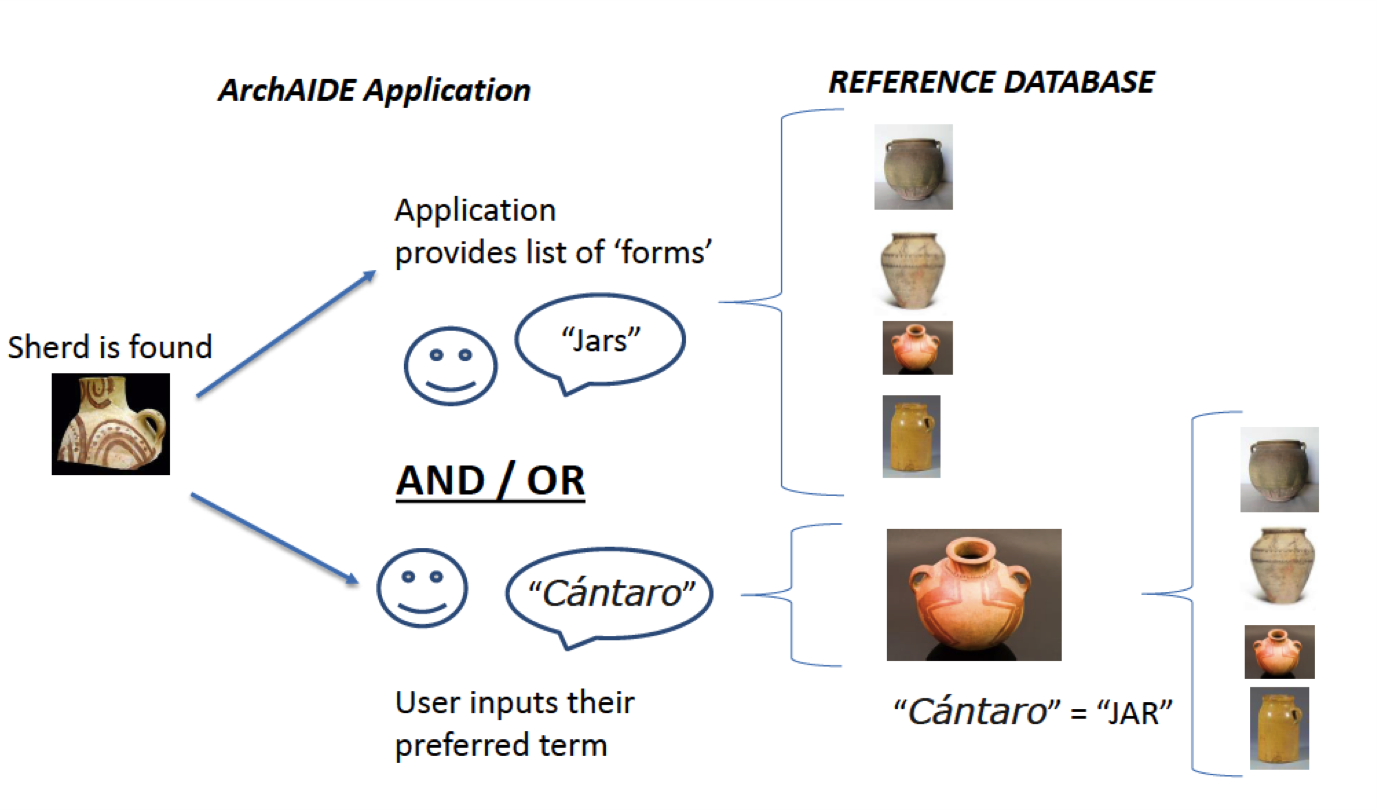
From the outset of the project, it was clear that a significant component of the ArchAIDE Reference Database would be the ability to contain multilingual vocabularies, to enable linguistic interoperability within the dataset being assembled. However, early in the discussions, project partners quickly identified semantics difficulties when faced with the task of describing either a fragment, or a whole vessel. For example, the difference between what may be referred to as a 'dish', 'plate' or 'platter', even though the physical shape may be similar or the same. Furthermore, it was necessary to establish a scheme of recording that was not only consistent across languages, but also archaeological traditions. Archaeologists working in different countries may not only use different words but also varying hierarchies or classifications for how they categorise an object. As a hypothetical example, one tradition may have four different words to categorise a candlestick, while another tradition may simply have one. These issues around semantics apply broadly across most areas of archaeological research, not only within the pottery specialism, so this solution is likely to be useful for a wide range of archaeological material.
The solution was the creation of a discrete set of vocabularies to account for, and reconcile these differences (Figure 8). These were used as the data forming the backbone of the ArchAIDE Reference Database, allowing different catalogues, and therefore different classification schemes, to be cross-searched and then presented by the ArchAIDE application. Following the precedent set by the EU Infrastructures ARIADNE project (Aloia et al. 2017), the vocabularies were built to create a resource with maximum interoperability for current initiatives and future projects. This was achieved through taking a Linked Data approach. The initial mapping exercise established a concordance between ArchAIDE and a neutral Linked Open Data (LOD) vocabulary. The creation of LOD for ArchAIDE allowed project data to be easily cross-searched as part of the wider Semantic Web, a format that lends itself to use through a range of methods and processes that utilise established web protocols and standards to interact with and retrieve data.
Each of the ArchAIDE archaeological partners worked through their catalogues and identified the descriptive terms that refer to, or classify, significant elements of a ceramic form. Learning from the methodology and using the tools developed for the ARIADNE project by the Hypermedia Research Group at the University of South Wales (Binding and Tudhope 2016), using a neutral spine to which partners could map these terms was deemed a preferable solution to establishing a new thesaurus bespoke to the project. As with the ARIADNE project, use of Getty Institutes Art and Architecture Thesaurus (AAT), proved a suitable candidate, with the added value of interoperability with ARIADNE and any other data also mapped to the AAT, thus giving the mapping work done by ArchAIDE a strong sustainable base. In the initial phase of the project all partners agreed on a subset of AAT terms that could be used for this neutral spine, describing the following methods of recording pottery from archaeological excavations:
Later in the project, partners established a need for controlled terminologies to describe the type or characteristics of specific parts of a ceramic vessel. As an alternative, and as a concerted effort to ensure that ArchAIDE data was interoperable with past and future projects, the project used the concepts of recording established by the original creators of the Roman Amphorae: a digital resource. The ArchAIDE multilingual vocabularies are now freely available for download and reuse from the ArchAIDE Portal for Publications and Outputs. They are available in Catalan, Dutch, French, German, Italian, Portuguese, Spanish and English, in both CSV and as LOD in Windows NT format.
Internet Archaeology is an open access journal based in the Department of Archaeology, University of York. Except where otherwise noted, content from this work may be used under the terms of the Creative Commons Attribution 3.0 (CC BY) Unported licence, which permits unrestricted use, distribution, and reproduction in any medium, provided that attribution to the author(s), the title of the work, the Internet Archaeology journal and the relevant URL/DOI are given.
Terms and Conditions | Legal Statements | Privacy Policy | Cookies Policy | Citing Internet Archaeology
Internet Archaeology content is preserved for the long term with the Archaeology Data Service (ROR). Help sustain and support open access publication by donating to our Open Access Archaeology Fund.