![]()
![]()
![]()
![]()
The theory of Bayesian wiggle-matching has been developed in full in Christen and Litton (1995), and in general, the theory of Bayesian Calibration has been developed in Buck et al. (1991); (1992); Christen (1994a); Christen and Buck (1998); Buck and Christen (1998), Gomez-Portugal Aguilar et al. (2002); Nicholls and Jones (2001), among others. Here the theory of wiggle matching is briefly presented, plus a further consideration to deal with outliers.
Let y = (y1, y2, ym) be a series of radiocarbon determinations with their corresponding standard errors σ1, σ2, ... ,σm, and their associated calendar ages θ = (θ1, θ2, ... , θm) (that is, the calendar ages at which each sample radiocarbon dated ceased metabolising). The output of a radiocarbon analysis, as provided by the laboratory, is an estimated date in the radiocarbon scale (yj) and a standard error (σj). The standard error reported is calculated using both empirical and theoretical considerations and the usual assumption is to consider it as known (see below). Here, we assume that θi - θj it is known exactly; most likely the radiocarbon dated samples were taken from chunks of tree-rings in a log or timber. The model we use is the following
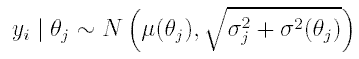
where μ (θj) is the piece-wise linear calibration curve (we are using the INTCAL98 calibration curve, see Stuiver et al. 1998) and σ2(θj) is a variance term arising from the errors observed in the calibration curve (see Christen and Litton 1995 and Christen 1994a). We also assume that ƒ(y | θ) = π mj=i ƒ(yi | θj) (conditional independence). That is, σj is assumed known, which is the usual assumption in radiocarbon dating, and the determinations are considered as conditional independent.
The piece-wise linear calibration curve is defined as
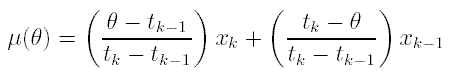
and the variance term is defined as
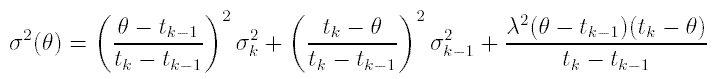
for tk > θ >= tk-1; where tk ± σk is the pooled radiocarbon determination for the calibration curve at knot (calendar year) xk. λ is taken to be 19 (see Christen and Litton 1995 and Christen 1994a), although Gomez-Portugal Aguilar et al. (2000) argue that a lower value could be used.
The definition of σ 2(θ) is based on a Brownian bridge model (see Billingsley 1999, 93) and represents a simple, although realistic, way to include the errors in the calibration curve (see Christen and Litton 1995; Christen 1994a; Gomez-Portugal Aguilar et al. 2002 and Nicholls and Christen 2000 for a more in-depth discussion). The option where no errors are included in the curve is covered simply by fixing σ 2(θ) = 0.
In many applications, and for practical reasons, the inclusion of the errors in the calibration curve is neglected. This is in fact good practice, as the variance in the posterior is comparatively higher than the variances in the curve. This is normally not the case in wiggle-matching because of the increased precision arising from the simultaneous calibration of several radiocarbon dates, even if the individual standard errors are big.
Let us assume that θ1 <= θ2 <= ... θm and that θ0 is the (unknown) calendar date for the event to be dated (this event may or may not coincide with any of the θj). We assume that θj = θ0 + αj where, as mentioned above, αj is known exactly (αj could be negative). The only unknown parameter then is θ0 and its posterior density is given by
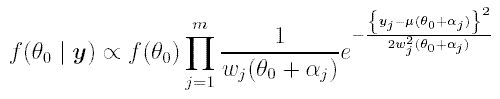
where wj2 (θ) = σj2 + σ 2(θ). The prior f(θ0) is an uniform distribution provided by the user (upper and lower bounds for θ0). This posterior is normalised numerically and provided as a histogram, both with (see Figure 2) and without (see Figure 1) considering the errors in the calibration curve. (Unfortunately Bwigg only allows for uniform priors, although mexcal could be used directly to consider more sophisticated priors. This feature is not yet included in Bwigg.)
The analysis of 'shift outliers' is based on Christen (1994b). A shift in the radiocarbon scale δj is considered for each determination, having a priori distribution
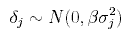
We fix β = 2. The latent variable Φj = 0,1 is also introduced. If yj is an outlier then Φj = 1, and thus needs a shift δj in the radiocarbon scale to be corrected. The following model [2] is assumed:
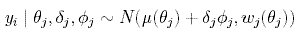
Interest then focuses on approximating P(Φj = 1 | y), the posterior probability of determination j being an outlier. MCMC is used to approximate P(Φj = 1 | y). In turn, a simulation is run from the full conditionals of each of the Φj's (Bernoulli distributions) and δj's (normal distributions, see Christen 1994b). To simulate from θ0, a proposal is simulated θ0' form f(θ0) and accept it with probability
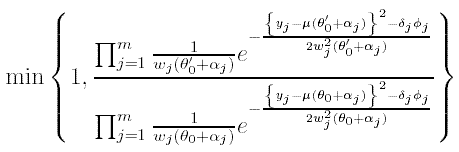
The resulting MCMC is very well behaved in that the support of f(θ0) is not too wide in comparison to the main bulk of the posterior for θ0. 10,000 samples are taken, every 10 passes, with a burn-in of 1,000 passes. This is usually enough for approximating P(Φj = 1 | y).
Footnote 2: Note that the errors in the calibration curve are taken into consideration via wj(θj)
![]()
![]()
![]()
![]()
© Internet Archaeology
URL: http://intarch.ac.uk/journal/issue13/2/4tech.html
Last updated: Thu Jan 23 2003