This section describes how a printed artefact catalogue was converted into electronic data, which could then be used as a basis for plotting artefact distributions. This process involved the following four steps (see also Figure 14).
The printed artefact catalogue of the Roman military fortress of Vetera I (Hanel 1995) provided the source data for this project, a sample of which is included in this paper. The catalogue was scanned at a resolution of 300 dpi into TIFF files using a scanner that allowed the compilation of multiple-page images. The TIFFs were then converted into digital text using ABBYY FineReader optical character recognition (OCR) software. Overall, the OCR software produced highly reliable data from the TIFF scan images, although OCR's reliability decreased significantly in scans of less than 300 dpi resolution. FineReader was also able to read and convert German characters into electronic form and check the spelling of the resulting text, speeding up verification of the OCR output. The capacity of FineReader to batch-process multiple TIFFs greatly improved the speed and efficiency of the OCR process. The OCR output was saved as Microsoft Word files.
Although FineReader produced editable digital files of the printed text, the information they contained was not in the correct format for use in either the relational databases or GIS data tables. Information about each artefact in the printed catalogue was presented as a continuous block of text, arranged in groups following a typological classification. For this information to be useful, it had to be re-arranged into a data matrix, which could then be queried to provide a quantitative summary of the total number and range of artefacts found at each excavation location, classified by use, gender, status etc. This transformation was the most time-consuming step in the data generation and manipulation process.
Although labour intensive, the most convenient and quickest way of re-formatting the catalogue was manually, using search and replace tools in Microscoft Word and Microsoft Excel. Basic formatting of the OCR text files was done in Word, with the formatting of the data matrix done in Excel. Macros could have been written to perform the task if each catalogue entry was identically formatted. However, this was not the case and in most cases printed catalogue entries were reduced to the bare minimum of descriptive information with empty descriptive categories simply left out.
The first step was to split the OCR text output into rows, one for each catalogue entry. This was largely done automatically by the OCR programme, but was also checked by eye. Each row was then split into a series of cells by inserting tab-stops in the Word documents at the point where cell boundaries were required. Information concerning artefact catalogue number, description, measurements, provenance or illustrations was put into a separate cell. Vetera's printed catalogue contained convenient abbreviations at the start of each sub-section, signifying the type of information it contained. These abbreviations could be replaced at one stroke with tab-stops using the find and replace tool in Word. Once rows were arranged and cell boundaries defined, the text was simply copied and pasted into a new Excel worksheet. Excel automatically separated the data into cells and rows using the paragraph marks to signify row-endings and tab-stops to signify cell boundaries within those rows. As mentioned above, each catalogue entry contained a slightly different range of information. For example, some had long descriptions with measurements, illustration references and notes, while others contained only a basic description and provenance. This meant that each electronic catalogue entry initially contained a different number of cells when pasted into the Excel spreadsheet.
To enable the information to be queried in a database, the cells had to be arranged into single coherent fields, each containing only one type of information (e.g. description, provenance etc.). This was not the case when the data were first pasted into Excel, as the catalogue entries contained a varying number of cells (see above). Fields had to be correctly aligned by 'dragging and dropping' the cells for each catalogue entry into the appropriate field. While this process was time-consuming, it was not easily achieved by any other means and provided ample opportunity for eliminating mis-spellings and other errors generated during the OCR process.
Once the information derived from the OCR process was formatted correctly, additional information, such as typological group, material and the all-important interpretative categories (gender etc.) were added in new fields. Information about typological group and material was included in the printed catalogue only as section headings, so this information had to be added to each individual catalogue entry. The interpretative category data was new and was added in by Allison (see 3.2.). Another addition to the data table was the insertion of SQL-consistent abbreviations of the descriptive fields, used as field names in the summary artefact queries. These were necessary because, to run successfully, ArcGIS required SQL consistency for field names, whether data were added to the GIS project by a direct connection to Access using the OLE DB provider for ODBC driver, or by importing separate Dbase IV (.dbf) format tables. The abbreviations had to be a maximum of 8 characters long and to contain only alphanumeric characters or underscores. Clearly, some classification groups did not fit this format (e.g. tableware and serving?/food preparation?). A standard set of abbreviations was used (see Figures 10 and 11). (See Section 7.2).
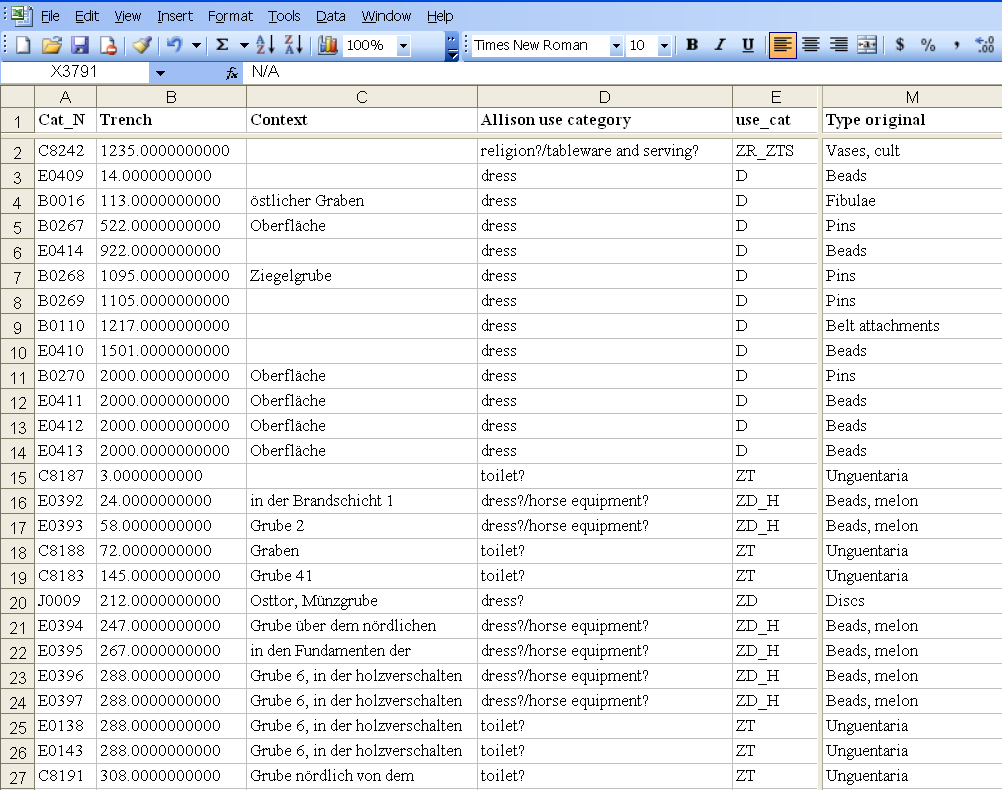
Figure 16: Screen dump of part of Excel spread sheet showing data from OCR translation of scanned original catalogue and added data for categories and their SQL abbreviations.
The result of this process was a digital version of the artefact catalogue containing the descriptive information for each catalogue entry in a single row of data cells, arranged into fields, each of which contained a single type of information, such as provenance, use category or gender (Figure 16). The transformation from the printed page to data matrix, with the addition of interpretative categories, meant that rather than being simply an electronic translation of the original catalogue, the electronic version was a greatly transformed dataset.
Once the artefact catalogue spreadsheets were fully formatted (see section 9.1) and contained all the necessary data, the next step was to transfer them to a database programme where queries could be used to produce the summary quantitative data plotted in ArcGIS.
© Internet Archaeology
URL: http://intarch.ac.uk/journal/issue17/4/7.1.html
Last updated: Mon Apr 4 2005
{kind=link}